Potential failure and associated operational downtime are real nightmares for businesses. In some industries, service disruptions can be disastrous, not least for financial reasons. Can we ensure that systems are as reliable as possible? How do you eliminate the risk of failure and ensure reliability at the highest possible level? The solution may lie in high availability services.
Table of contents
How much does downtime cost?
Do you know how expensive a minute can be? According to studies, the average cost of a minute of downtime of a system used by a large enterprise is between $5,600 to $9,000. In the case of small and medium companies, the cost of a minute of system downtime ranges from $137 to $427.
One of the biggest losses due to the outage was suffered by Amazon. In August 2013, Amazon’s online service and mobile app were unavailable for 15 minutes; each minute cost them $66,000.
To prevent such a costly downtime, high availability must be ensured. It may seem expensive to maintain, but it would surely be cheaper than potential losses due to a system failure.
What is high availability?
High availability (abbreviated to HA) is an approach that involves designing the infrastructure so that the application continues to function without interruption, even in the event of errors or failures. This includes the appropriate load balancing, scaling up in response to demand, or diversifying data and resources between different locations. In the case of a complete infrastructure shutdown, a high availability strategy must ensure that the system is operational in a backup data centre. The inauguration should happen in seconds or minutes.
The opposite of operational is unavailable. What’s the difference between unavailable and high availability? High availability ensures the application works continuously, while an unavailable system doesn’t operate and can’t be used.
It is not possible for the application to be 100% available due to, i.a., the introduction of updates, maintenance works, or emergency responses. In the industry, “five 9s” is considered high availability, meaning that the application has to be up for 99,999% of the year.
Some terms are associated with high availability, like fault tolerance, redundancy, or disaster recovery. Some mistakenly use them as synonyms; in fact, their definitions intermingle, yet still, those are separate concepts.
Fault tolerance vs high availability
Fault tolerance is a technique that aims to maintain the continuous operation of an application. It differs from high availability in that HA is intended to keep the uptime of the entire application uninterrupted, while fault tolerance allows users to continue using the system when facing a crash but with reduced functionality.
It has a more complex architecture and greater redundancy that preserve system operation in the event of component failure. The fault-tolerant system constantly monitors hardware performance and immediately activates the same resources on other operating servers in the event of a failure (the lack of response from a device or a component).
The introduction and maintenance of fault tolerance are more costly than “just” high availability, mostly because of higher capital and operating expenditures.
High availability vs redundancy
Redundancy is often a part of the high availability approach; however, high availability can exist without redundancy, and there’s no way that redundancy will be used when there’s no HA.
Redundancy constantly duplicates resources and spreads them between locations and devices, like there’s mirrored data on several servers. When one component shuts down, others have the same data and can instantaneously take over.
High availability vs disaster recovery plan
A disaster recovery plan is a document containing a description of procedures to follow in the event of an IT disaster – an incident taking place at an own data centre, a problem on the service provider’s end, malfunctioning of the app, a critical system error, or downtime in the availability of digital work tools. DRP it’s the ability of an application to quickly stand up.
If high availability ensures continuous application operation, disaster recovery aims to restore the application as soon as possible in case HA fails.
Here you’ll find more information about DRP: Disaster Recovery Plan – how to keep applications available when a failure strikes
How to achieve HA – tips and best practices
Scale resources and databases to fit the demand
One of the most common causes of system shutdown is infrastructure overload. To prevent this, it is necessary to scale appropriately in advance or, for example, in the cloud, to enable automatic scaling, which adjusts the level of consumption to the current load.
The same applies to databases, as these components are often prone to crashes, and if they do, data can be lost. One of the techniques of scaling databases is sharding which splits the database in half and runs them on different servers. Yet, some specialists don’t recommend it, as sharding translates into system complexity and increases the risk. In a public cloud, several database services (relational, NoSQL, key-value, document, or in-memory) automate many maintenance tasks, including scaling.
See also: Cloud SQL – a cloud database. What is it, and why is it worth using?
Use various server services
If your application is only running on one server and it shuts down, the application will not be available until the device reboots. To ensure greater availability and “independence” from infrastructure, it is highly recommended to distribute traffic among several servers or to deploy application components or contents on different virtual or physical machines.
Introduce clusters and load balancing
Hosting services often work together as a cluster, which means that nodes share the load between them (through load balancing) and constantly synchronise data, behaving like one server. When one instance or data centre is unavailable, another immediately takes over the traffic and service provisioning. The instances can also automatically diagnose and self-repair themselves.
Diversify data locations
Data and applications should reside in multiple locations; ideally, key components should be located in geographically distant and independent data centres. This is to prevent the system from being lost if any machines fail. Geo-distributing the separate application stack allows other elements to work without compromising performance in the event of a failure in another location.
Plan a recovery strategy
A disaster recovery plan should come in if high availability fails (e.g., due to a natural disaster that knocks down a data centre). The disaster recovery plan aims to make an entire app or its crucial parts work again in a stable manner and restore access to data as quickly as possible. A quick and well-thought-out response is to shorten the system downtime and mitigate the negative impact of the outage.
A disaster recovery plan should include, among others:
- a list of the digital tools in use and developed products,
- a list of the physical equipment and virtual assets in use, with the indication of the provider,
- a list of employees in charge of a given area,
- a list of details of the contact persons who need to be notified of the incident,
- a schedule of activities that need to be undertaken in the event of a given incident covering, e.g. a description of the incident, a description of losses, sending service outage notifications to users, an indication of the steps to follow to bring the system back to operation (e.g. the path to the backup file or a guide on how to launch the Disaster Recovery Centre),
- a description of actions that need to be taken after the system start, e.g., a load test, an analysis of the situation that has occurred, or a description of the event, the so-called post-mortem.
Cooperate with cloud professionals to ensure HA of your application
High availability architecture in Google Cloud
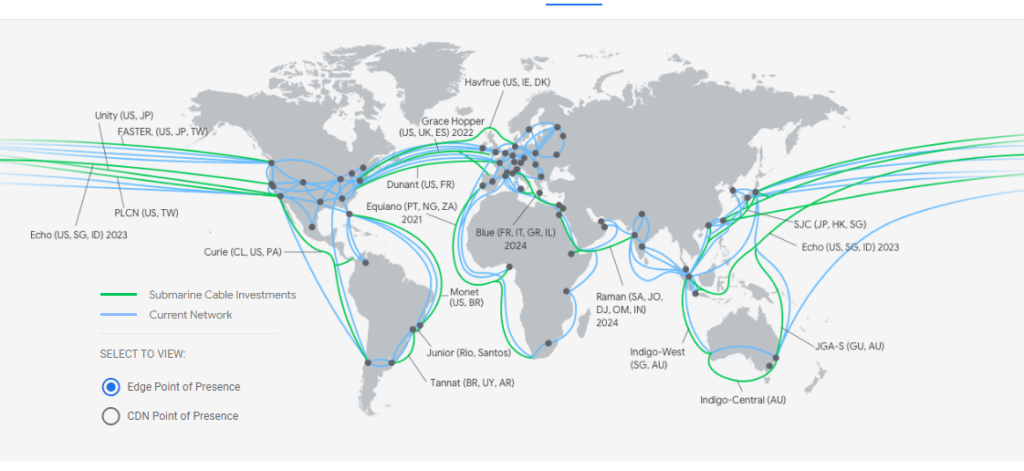
At the physical level, Google Cloud is millions of machines, hundreds of server rooms and tens of thousands of fibre-optic cables. At the virtual level, it is nearly 200 ready-made, advanced cloud services running on-demand, scalable, with high performance and 99.95% availability upwards.
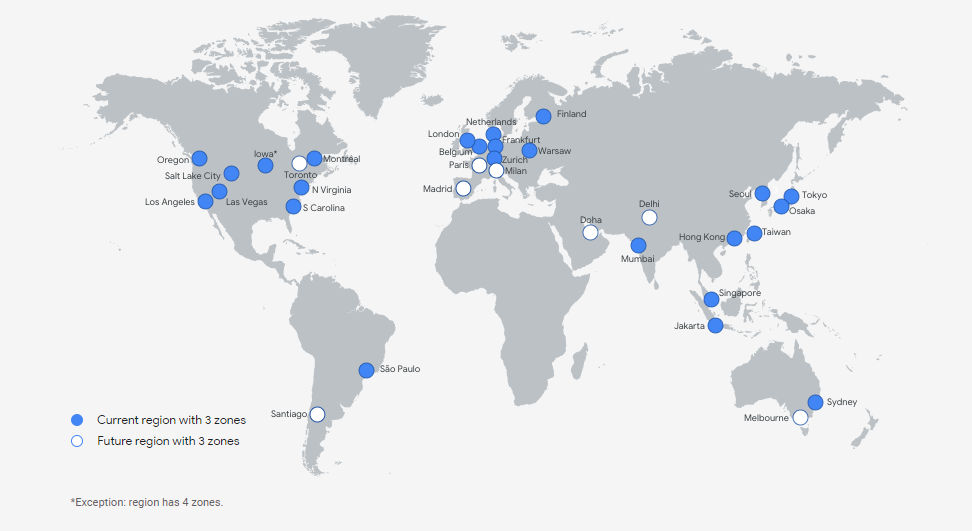
The Google Cloud Platform network spans the globe. It has 146 points of presence (PoPs), which translates into the availability of the platform in more than 200 countries and territories.
The Google Cloud structure is not limited to physical data centres. If you upload a file to the cloud, it will never be assigned to one machine in one building; it will be constantly copied and transferred between different devices and locations thanks to redundancy. This is due to the abstraction layer, designed to ensure the security and availability of customer data and applications even in the event of a natural disaster or incident in the provider’s data centre.
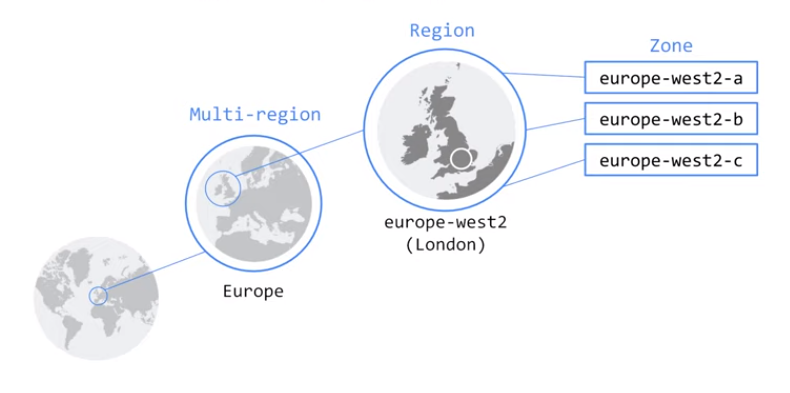
Such a single ”immaterial” centre for data is a zone. Three zones are connected to form a region. Resources can be run in the cloud:
- within a single zone – which is the cheapest solution,
- within a region, which allows high availability to be maintained even in the event of a single zonal failure,
- between regions (e.g. between continents) if the application has to be available globally.
Be up to date with cloud updates and connect with other GCP users