Table of contents
A database is an inseparable element of any application or an IT system. It retains new information and changes made by users, other devices or processes (e.g. on the ‘Internet of things’ platforms).
It is (largely) thanks to databases that after we open Facebook or another social media site, we don’t have to complete our profile from the scratch – because once entered information about the name, surname, college degree, as well as our posts, have been saved in the database and are available every time we log into the portal.
Databases also enable, among others:
- shopping in e-commerces,
- making deposits and withdrawals in banks,
- conducting accounting activities in companies,
- controlling the level of stock in stores,
- managing information coming from production lines.
Be up to date with cloud updates and connect with other GCP users
What is a database?
Let’s start with what the data is. Data is a collection of numbers and texts of various forms; in IT, data are the objects, on which programs operate. For example, the data can be your first name, last name and telephone number, and the processing “program” is a phone book (classic database example).
A database is an organized information storage system. The data is systematized, which makes it easier to manage.
The data collected and processed in IT systems or applications is often more complex than a list of names with an assigned telephone number. Its size can reach hundreds of terabytes, and many types of databases have been developed to collect and handle records. Currently, database systems can be divided according to the ways of data organization:
- flat-file databases – in a flat-file database, each table is an independent document and can’t cooperate with other tables, but the data in the flat-file database can be sorted and filtered; an example of a flat-file database is a spreadsheet containing a list of book titles with the author’s name and publication year assigned to them;
- hierarchical databases – data is stored as parent-child records, and the structure of a hierarchical database resembles a tree branching out;
- relational databases – in relational databases, tables are related to each other and can cooperate with each other, so obtaining the necessary information isn’t complicated; in relational databases, the SQL language is used to operate on data;
- object databases – their system is similar to object-oriented programming, and the data is defined and stored according to the object-oriented model,
- streaming databases – they operate on data streams, and the continuous query languages based on SQL are implemented in them,
- temporal databases – databases containing information on the time of entry and validity time of data; they are often administered automatically by deleting or archiving outdated data;
- non-relational databases – NoSQL databases, in which there are no tables and relationships, and the data doesn’t have to be homogeneous in terms of structure.
The most commonly used databases in programming are relational databases. Relational databases have internal programming languages that use SQL (Structured Query Language) to operate on data and create advanced support functions. The most popular relational databases are MySQL, PostgreSQL, and SQL Server.
What is Cloud SQL?
Cloud SQL is a service of Google Cloud Platform. It’s a cloud database service, or database-as-a-service (DBaaS). Data in the database is stored and processed in the cloud, on the infrastructure of a cloud service provider, and the access is provided from the level of the Google Cloud Platform console or the command line. This means that the application owner can use the computing power of Google Cloud, don’t have to waste time maintaining their own infrastructure, and can easily connect the cloud database service with other GCP services – for example, virtual machines or Kubernetes container management service.
Currently (November 2020) Cloud SQL supports three popular database systems:
- MySQL 5.6, 5.7 and 8.0,
- PostgreSQL 9.6, 10, 11, 12 and 13,
- SQL Server in 2017 version.
Database in the efficient Google Cloud
Cloud SQL is part of the Google Cloud Platform cloud infrastructure. GCP is a scalable and flexible solution with high efficiency and availability of services.
All Google Cloud machines are managed by the service provider. This means that by using the cloud, you don’t have to waste time maintaining or updating your equipment and you can still enjoy serverless services that are available in many regions and locations.
Google Cloud creates its own network of fibre-optic connections between data centres, which may be especially important for owners of applications with global reach. The transfer speed through the Google network reaches up to 10 Tbs, which enables increasing efficiency while maintaining the same price for the service. Moreover, Google Cloud guarantees service availability at the level of 99.95 –99.99%, which is the highest SLA among popular cloud service providers.
This means that Cloud SQL, as one of the GCP services, is a serverless, scalable service ensuring high availability and performance. As well as cost flexibility, as the use of Google Cloud computing power is counted per second (which you will read about in a moment).
You can read more about GCP in the article:
20 reasons to choose GCP cloud infrastructure
Extensive instance configuration options
In Cloud SQL, we have the option of a detailed instance configuration for each database system. The configuration of the service for the application requirements will translate into performance, but also price.
When creating an instance, we can choose:
- region and location of the new instance,
- virtual machine type, its memory and CPU; we can choose shared-core machines, standard machines or high memory machines;
- disc – SSD with higher speed and higher QPS (query per second), or HDD with lower price;
- capacity (data storage) ranging from 10 to 30720 GB; you can also set up an automatic (permanent) storage increase in case it’s needed.
Service scalability and cost flexibility
Since Cloud SQL uses the computing power of Google Cloud, the cost depends on the disk space used and the usage per second. If there are few queries to the database and the usage isn’t high, the cost of the service will be lower. When the application is under load (e.g. it will be used by several times more users than usual), the service will scale up, and Cloud SQL will easily handle all queries. The use of computing power will be higher, and the cost of the service will be proportional to consumption.
The price of the service also depends on our database system, instance configuration or region. In all cases, however, the cost is charged for actual usage, not for “rented in case” resources.
Reduction of maintenance costs thanks to automation
As I mentioned, Google Cloud Platform services are fully managed – and so is Cloud SQL. The Google team takes care of the physical infrastructure, which allows the user to transfer the maintenance costs to the development zone (in the case of Arena.pl, the transition to Google Cloud Platform allowed to reduce the internal infrastructure maintenance costs by 20-30% – see case study). Service automation not only allows for a reduction of internal costs, but also prevents from making mistakes.
A lot of automation can be implemented into the Cloud SQL service, which takes the strain off the technical team. You can automate, for example:
- database administration,
- management of database capacity and optimization of the occupied disk space,
- performing data backup and recovery.
Automatic backup creation
As early as at the instance configuration stage, GCP gives you the option to indicate a time window, in which automatic backup will be performed. Another recommended option is data recovery down to a fraction of a second, thanks to the binary log records. The backup can be stored in a different region than the instance is. Backup costs are calculated per gigabyte of data per month; the amount depends on the database system, region and instance configuration.
Data security in Cloud SQL
The Cloud SQL service is compatible with the SSAE 16, ISO 27001, PCI DSS and HIPAA security standards. The data is encrypted at rest as well as in transit. Cloud SQL supports connection with Virtual Private Cloud, and each instance has a firewall that enables controlling public network access. The database can only connect to the public network via SSL or Cloud SQL Proxy.
Easy integration with other GCP services
Applications that are outside of the Google Cloud environment can be connected to Cloud SQL. However, if you have the entire application or a large part of it in the Google cloud, you can achieve more, for example through connections between services.
Cloud SQL will work without any problems with other services from the Google Cloud Platform offer, including the Compute & Serverless group: Compute Engine, App Engine, Kubernetes Engine, Cloud Run or Cloud Functions. You can involve BigQuery – a data warehouse service – for quick database queries and carrying out immediate analytics.
You can read more about connecting Cloud SQL to the BigQuery service on the Google Cloud website: Cloud SQL federated queries.
Fast startup and easy migration
A Cloud SQL service instance can be easily created and configured from the Google Cloud console. The whole process consists of a few clicks and filling in a few fields. You can learn just how easy it is to create a Cloud SQL instance from the tutorial below.
After configuring and starting the service, you can move your database to Cloud SQL. The process is clearly described in the console, and the service has built-in tools to carry out the migration. Performing the migration is not bothersome (in many cases, you don’t even have to make changes to the application code), only the database import itself may take some time.
How much does Cloud SQL cost?
Payments for the Cloud SQL service depend on the use and occupied space. The final price consists of several factors, including:
- database system used – fees are different for MySQL, PostgreSQL and SQL Server,
- region and location of an instance,
- CPU and virtual machine memory,
- disk type and space used,
- high availability option,
- network and method of data transmission,
- held licences.
You can calculate the final cost of the service in the Google Cloud calculator, or contact FOTC for estimation. Additionally, by establishing cooperation with an official Google Cloud Partner, you will get a $500 voucher to be used on Google Cloud Platform.
Find out more about the Google Cloud Platform
Contact us to receive a $500 voucher for GCP
Collaborate with FOTC to obtain a $500 voucher for the service and get 24/7 technical support
How to start and configure the Cloud SQL service? Tutorial
To run the Cloud SQL service, you must have an active account on the Google Cloud Platform.
Enter the Google Console at https://console.cloud.google.com/.
From the left-side menu, select SQL.
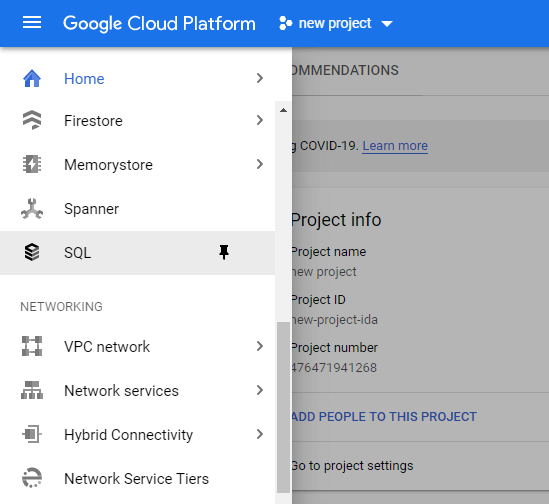
Next, select a database system. Regardless of the database selected, the next configuration steps will be the same.
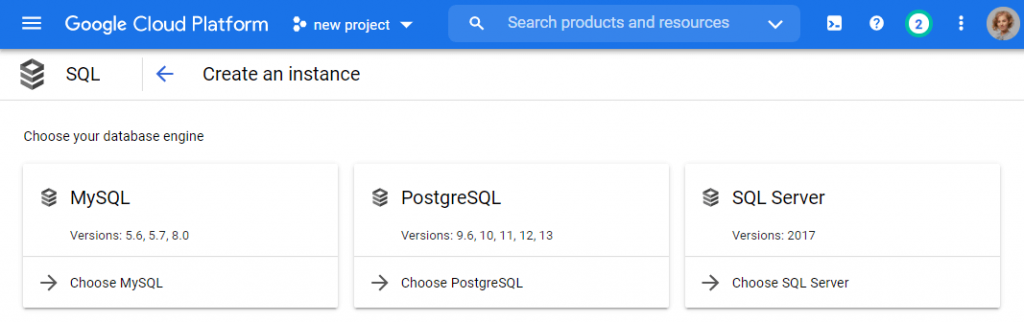
Fill in the instance name and password.
Select a region. You can leave the zone to be automatically filled in by Google – it won’t affect the cost or efficiency of the service.
Select the database version you have.

Expand “Show Configuration Options”. You’ll be able to configure networks there, select the type of virtual machines, disk type and space, or set up making automatic backups.
First on the list are the connection settings.
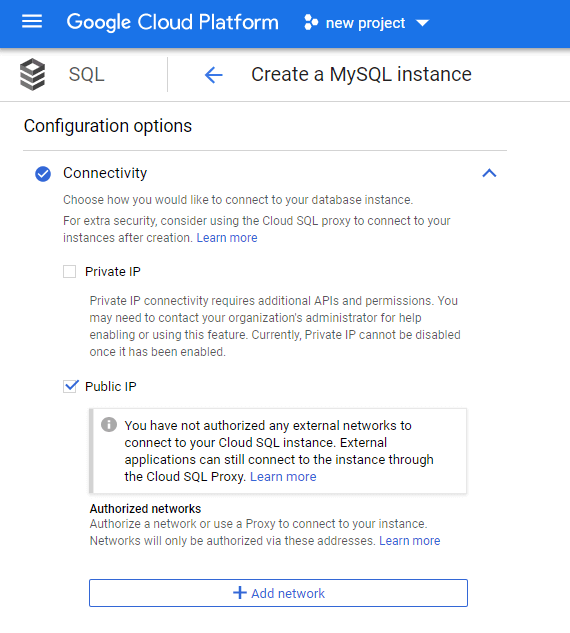
In the “Connectivity” option you can set the method of connecting to the database instance – via private IP or public address. To connect via a private IP address, it’s necessary to use, among others, Compute Engine API or Service Networking API. When selecting the “Public IP” option, you should add the networks that will connect with the instance via Cloud SQL Proxy.
Next, go to “Machine type and storage”.
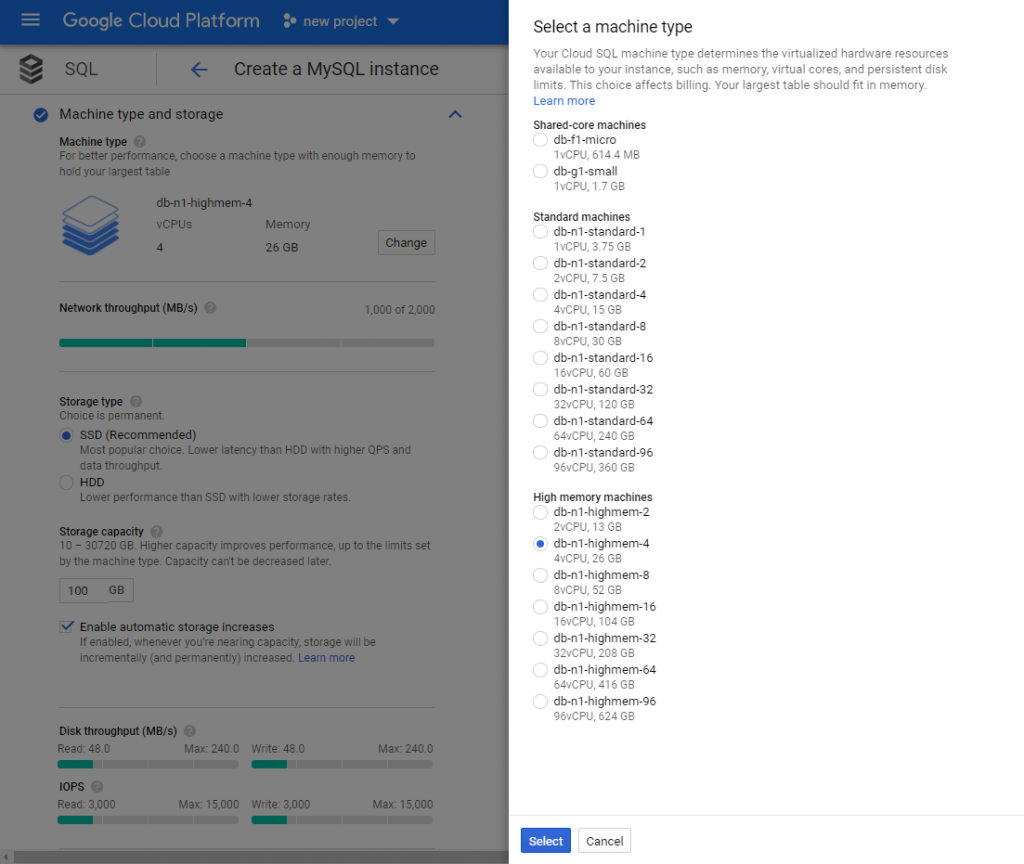
You can choose the type of virtual machine here. You can choose between shared-core machines, standard machines and high memory machines.
Next, select the disk type – SSD for high speed and more queries per second, or the more cost-effective HDD option.
Indicate how much data storage capacity you need (ranging from 10 GB to 30720 GB). The higher the value you indicate, the better the performance of the Cloud SQL instance will be. You can enable the option of automatic (permanent) storage increases to maintain high performance.
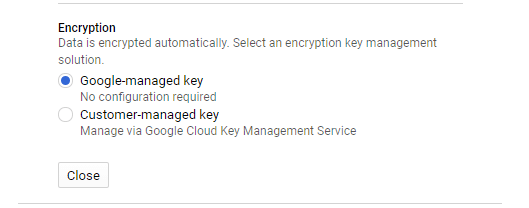
Choose data encryption method – with a Google key or your own Google Cloud Key Management Service key.
Go to “Backups, recovery, and high availability”.
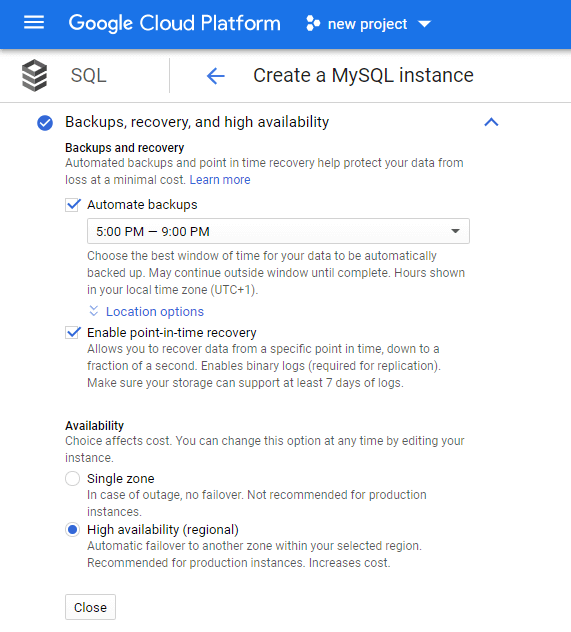
If you want to use the automatic backup option (which is highly recommended), select the backup time window. You can choose the region where the backup will be saved.
By default, the data recovery option is also selected, which enables the record of binary logs.
If you want high availability of the service, check the “High availability (regional)” option. In case of emergency, the service will be switched to another instance and high availability will be maintained. Note – this involves additional costs.
After completing the configuration, click “Create”. Creating the instance may take several minutes.
You will see the Cloud SQL instance panel, where you can find information about the service, the option to edit the configuration, record of operations and logs or maintenance settings. In the chart at the top, you can monitor your CPU usage, disk and memory usage, incoming and outgoing bytes, and a number of queries per second.
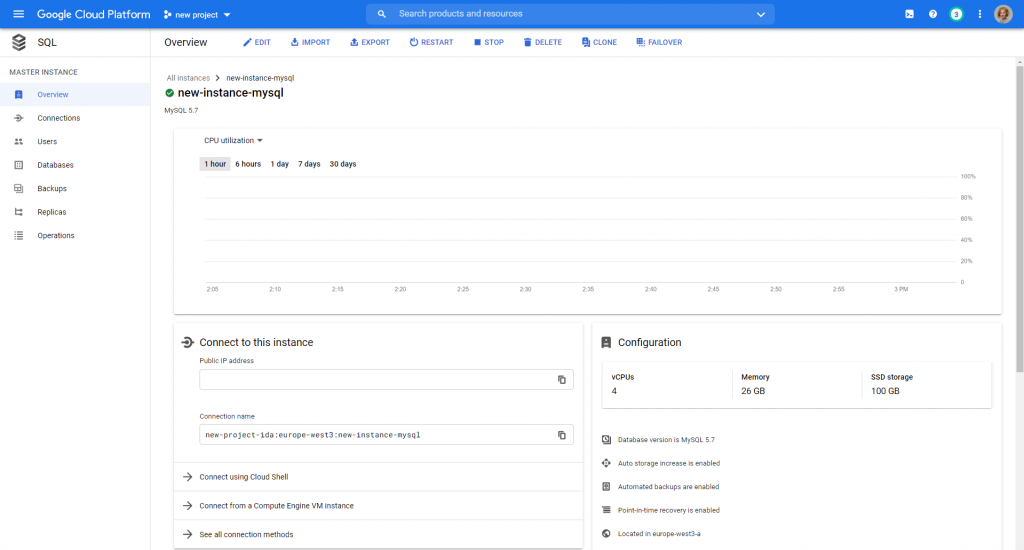
And that’s all about Cloud SQL. In case you have trouble, contact us – we will be happy to help!
Download a free ebook and learn how to secure your cloud infrastructure from the ground up