Table of contents
What is Dataflow? The service overview
Dataflow is a serverless, latency-minimising, cost-flexible, secure stream data and batch data processing cloud solution. The idea behind the service is to eliminate the need for complex operations and maintenance by automating infrastructure provisioning and scaling. The service provides flexibility, thanks to horizontal and vertical scaling, which enables the management of seasonal and spiky workloads without overspending. It allows businesses to look at the whole picture, have full control over processes of data ingest, and enhance the speed and performance of a product or application.
In other words, GCP Cloud Dataflow is a data pipeline service that allows you to implement streaming in Apache pipelines, which you can build using the Apache Beam library.
Dataflow features and advantages
- Dataflow programming languages – Google Dataflow supports programming languages such as Python, Java, and Go.
- Vertical and horizontal autoscaling that dynamically adjusts compute capacity to the demand,
- Smart diagnostics enabling SLO-based data management, job visualisation capabilities, and automatic recommendations for improving performance,
- Streaming Engine that moves parts of pipeline execution to the service’s backend, decreasing data latency,
- Dataflow Shuffle moves operations of grouping and joining data from VMs to the Dataflow’s backend for batch pipelines that scale seamlessly,
- Dataflow SQL enables the development of streaming Dataflow pipelines using SQL language,
- Flexible Resource Scheduling (FlexRS) reduces batch processing costs thanks to scheduling and combining preemptible VMs with regular instances,
- Dataflow templates made for sharing pipelines across the organisation,
- Notebooks integration that enables the user to create pipelines with Vertex AI Notebooks and deploy them using Dataflow runner,
- Real-time change data capture for synchronising and replicating data with minimum latency,
- Inline monitoring that lets the user access job metrics to help with troubleshooting batch and streaming pipelines,
- Customer-managed encryption keys to protect batch or streaming pipelines with CMEK,
- Dataflow VPC Service Controls, integration with VPS Service Controls for an additional security layer,
- Private IPs provide greater security for data processing infrastructure and minimise the level of consumption of Google Cloud project quota.
Subtypes of the service
Google Cloud made three subtypes of the service:
- Dataflow Prime – a service that scales vertically (adding more instances) and horizontally (increasing machine specifications, adding CPU and memory) for streaming data processing workloads. Dataflow Prime allows you to create more efficient pipelines and add insights in real time.
- Dataflow Go – a service offering native Go programming language support for batch and streaming data processing workloads. It leverages Apache Beam’s multi-language model to exploit the performance of Java I/O connectors with ML transforms.
- Dataflow ML – dedicated to running PyTorch and scikit-learn models directly within the pipeline. It allows the implementation of ML models with a little code. Dataflow supports the implementation of ML models, including by accessing GPUs or systems to train models, either directly or via frameworks like Tensorflow Extended (TFX). Dataflow ML is an extension for these functionalities.
Be up to date with cloud updates and connect with other GCP users
When it’s worth using Dataflow?
Dataflow is an excellent offer for applications such as real-time artificial intelligence, data warehousing or streaming analytics. In what situations will Dataflow work? You can use it for research and retail segmentation, clickstream, or point-of-sale analysis. The service will also help detect fraud in financial services, personalise game user experience and support IoT analytics in industries such as manufacturing, healthcare, or logistics.
One of the Dataflow customers is Renault. As early as 2016, the French car brand started a digital transformation as part of its alignment with Industry 4.0, which resulted in the implementation of Google Cloud infrastructure. Since then, the Dataflow service has become the primary tool for most of the platform’s data processing needs. As a result, Renault uses Dataflow to quickly extract and transform data from production sites and other connected key reference databases.
Here you’ll find information about Google Dataflow best practices: Tips and tricks to get your Cloud Dataflow pipelines into production
How much does Dataflow cost?
Like most services within Google Cloud, Dataflow also operates on a pay-as-you-use model. The usage is billed for resources your jobs consume, i.e., the region in which jobs run, type of VM instance, CPU per hour, memory per hour, or the volume of data processed. The rate for pricing is based on the hour, but Dataflow usage is billed in per-second increments per job basis. When Dataflow works with other services, such as Cloud Storage or Pub/Sub, the costs of these services will apply separately.
One of Dataflow’s pricing features is Flexible Resource Scheduling (FlexRS), which combines preemptible VMs in a single Dataflow worker pool, ensuring cheaper processing resources.
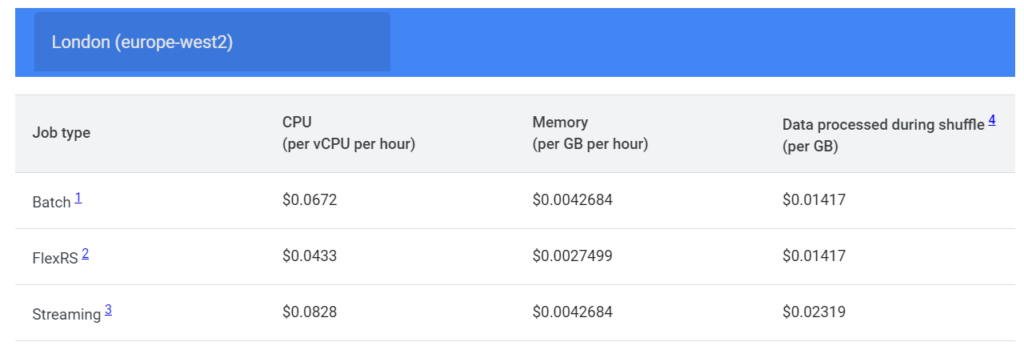
Below are examples of Dataflow prices billed for one-hour usage, for the London (europe-wst2) region, with instance configurations:
- for Batch: 1 vCPU, 3.75 GB memory, 250 GB Persistent Disk if not using Dataflow Shuffle, 25 GB Persistent Disk if using Dataflow Shuffle;
- for FlexRS: 2 vCPU, 7.50 GB memory, 25 GB Persistent Disk per worker, with a minimum of two workers;
- for Streaming: 4 vCPU, 15 GB memory, 400 GB Persistent Disk if not using Streaming Engine, 30 GB Persistent Disk of using Streaming Engine.
See also: