Infrastructura este ”sufletul” multiplelor afaceri contemporane – în special a celor care dezvoltă și oferă produse digitale. Conceptul de „infrastructură” include numeroase elemente: servere, mașini virtuale, memorie, baze de date, rețele, servicii de cloud computing și multe altele. Toate implică nevoia unui instrument de monitorizare care să ajute la planificarea capacității acestora și să prevină în cele din urmă problemele de performanță. Aici intervine conceptul de Cloud Monitoring – un serviciu Google Cloud. Acesta vă permite să monitorizați fiecare element al infrastructurii, chiar și în modelele multi-cloud sau hibride.
Pentru a asigura disponibilitatea și stabilitatea produselor și, în același timp, pentru a menține un ritm alert de dezvoltare, organizațiile trebuie să monitorizeze continuu fiecare departament ce ține de infrastructură. Sunt necesare răspunsuri rapide în caz de defecțiuni și, în mod ideal, identificarea potențialelor incidente și amenințări înainte ca acestea să apară.
Ce este Google Cloud Monitoring?
Cloud Monitoring este un serviciu cloud Google care măsoară serviciile Google Cloud, precum și infrastructura multi-cloud (de exemplu, GCP + AWS) sau cea hibridă. Acesta colectează informații despre starea serviciilor și a aplicațiilor, disponibilitate și performanță și le prezintă sub formă de liste, tablou de bord de monitorizare sau diagrame generate automat. Cloud Monitoring vă ajută cu răspunsuri la întrebări precum:
- Sunt disponibile și funcționale serviciile și aplicațiile care rulează?
- Care este încărcătura unui anumit serviciu?
- Care este timpul de funcționare al unui anumit serviciu?
- Este funcțional site-ul web sau există probleme de performanță?
- Cum performează serviciile, aplicațiile și site-urile mele?
Setarea alertelor
Pe lângă prezentarea rezultatelor sub formă de grafice, Cloud Monitoring ajută și la planificarea capacității sarcinilor și vă permite să setați alerte corespunzătoare. Sistemul de notificare (pe lângă mesaje text și e-mailuri) poate fi integrat cu instrumente externe ca Slack sau PagerDuty. Fiecare notificare poate fi corelată cu documentația și instrucțiunile necesare pentru a răspunde rapid unui anumit incident.
Citiți mai multe pe subiect: De ce necesită compania ta un Business Continuity Plan?
SRE – ce este Site Reliability Engineering?
Site Reliability Engineering (SRE) este un concept care sprijină crearea de aplicații sau programe scalabile și extrem de fiabile. Vă permite să găsiți un echilibru între viteza mare de dezvoltare și stabilitatea elementelor ulterioare ale sistemului. Activitățile SRE au scopul de a minimiza erorile și eșecurile prin monitorizarea continuă și automatizarea sarcinilor efectuate.

Ce puteți monitoriza cu Google Cloud Monitoring?
La crearea unui proiect Google Cloud, veți putea rula automat serviciul Cloud Monitoring. Dacă doriți să acordați acces unui alt utilizator, asigurați-vă că rolul atribuit include permisiuni pentru a edita serviciul de monitorizare.
Cloud Monitoring vă permite să vizualizați și să gestionați datele proiectelor voastre pentru:
- Un singur proiect Google Cloud,
- Mai multe proiecte din cadrul organizației,
- Mai multe proiecte Google Cloud în cadrul mai multor organizații,
- Cel puțin un proiect Google Cloud și orice număr de conturi AWS,
- Cel puțin un proiect GC și o infrastructură locală.
Lansați serviciul sub îndrumarea experților cloud FOTC
Lansarea serviciului Cloud Monitoring
Pentru a accesa serviciul, trebuie să fii conectat la consola Google Cloud și să selectezi proiectul pentru care urmează să creezi monitorizarea.
Pentru a porni serviciul, selectează Monitoring din meniul din stânga.
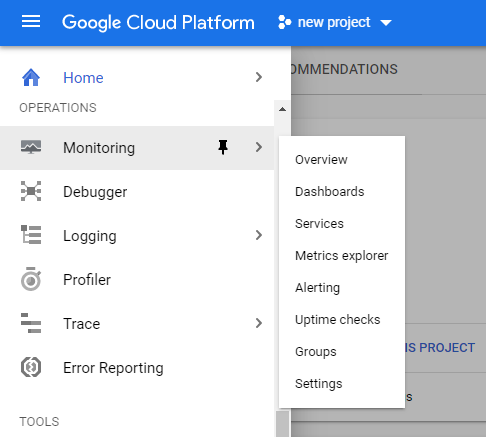
Ți se va crea automat un panou care va conține rezumatul proiectului.

Panoul respectiv conține un set complet de informații – tablou de bord, notificări și verificări de disponibilitate. Acesta îți va permite să evaluezi starea infrastructurii utilizate în proiect și elementele cele mai importante ale acesteia:
- O listă cu resursele monitorizate, în tabelul din stânga (Resources Dashboard),
- O listă a regulilor de control acces și rezultatele acestora, împărțite în funcție de locații (Uptime Checks),
- O listă de resurse grupate, cu avertismentele lor respective de găsit în partea de jos (Groups),
- Un tablou de bord cu incidentele curente și cele încheiate (Incidents). Conține și evenimente care au încălcat normele stabilite și au declanșat astfel o alertă.
- Diagrame cu informații despre serviciile monitorizate în proiect (Charts).
Urmărirea jurnalelor
În panou, poți accesa și vizualizarea jurnalelor de eveniment (Logging or Trace) – un serviciu pentru a monitoriza întârzierile și localiza blocajele.
Dacă vrei să urmărești concomitent mai multe proiecte, ar trebui să creezi un reper măsură pentru mai multe proiecte – o gamă de valori care acoperă mai multe proiecte.
Agentul de monitorizare
Cloud Monitoring poate accesa anumite măsurători ale mașinilor virtuale utilizate (CPU, trafic pe disc, trafic în rețea, informații despre disponibilitate) fără a folosi agentul de monitorizare. Cu toate acestea, pentru a obține acces la resurse suplimentare de sistem și la servicii de aplicație, trebuie să instalați Agentul de monitorizare.
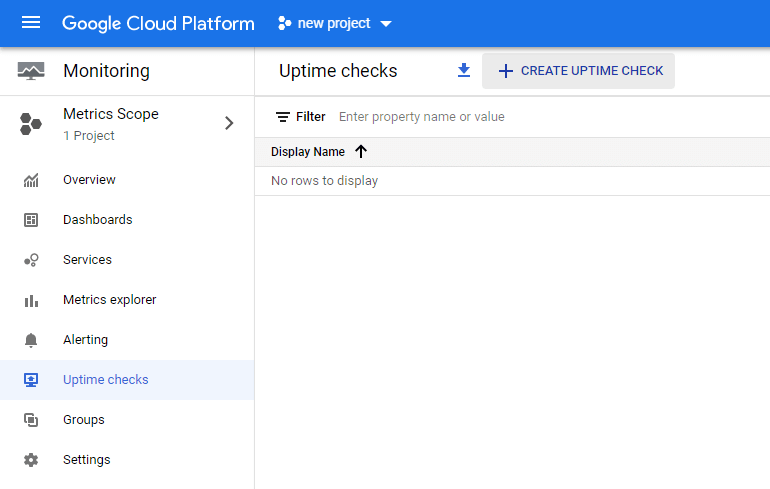
Verificări de uptime – reguli de control al disponibilității
Verificările de accesibilitate (uptime checks) sunt solicitările trimise resurselor pentru a verifica dacă acestea răspund și funcționează corect.
Folosind uptime check, puteți verifica disponibilitatea serviciilor publice în locații din întreaga lume. Cloud Monitoring vă oferă opțiunea de a verifica starea aplicației dvs. App Engine, a URL-ului gazdă, a instanței Compute Engine, a instanței AWS sau a Elastic Load Balancer (sistemul de echilibrare a încărcăturii în cloud al Amazon). În configurația de verificare a timpului de funcționare, trebuie să indicați protocolul de rețea – HTTP, HTTPS sau TCP. Puteți crea o politică de alertă pentru fiecare regulă și puteți vizualiza informații despre timpul dintre trimiterea cererii și primirea răspunsului din fiecare locație.
Pentru a crea o verificare a disponibilității, selectați Monitoring in the menu, apoi Uptime check și apăsați apoi pe Create uptime check (în partea de sus a ecranului).
Se va deschide o fereastră în care vom crea o regulă de control al accesibilității cu condițiile indicate.
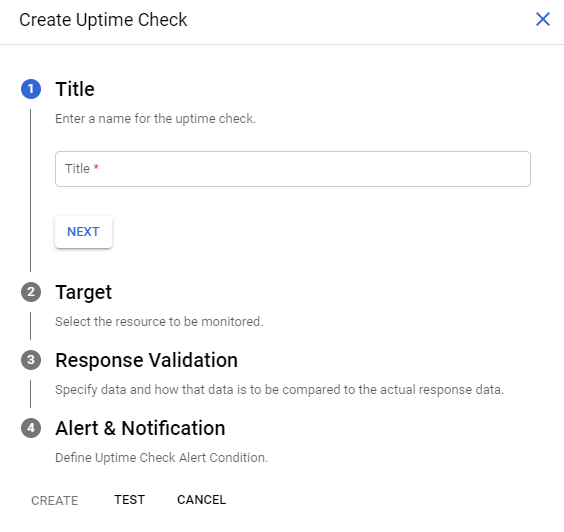
Exemplu de verificare a timpului de funcționare
Exemplul de mai jos verifică disponibilitatea HTTP. Resursa este verificată în fiecare minut cu un timeout de 10 secunde. Verificările uptime care nu răspund în această limită sunt considerate un eșec.
Mai jos sunt exemple despre cum poate arăta starea vizibilă în panoul principal de verificări
Uptime și în panourile detaliate.
1. Eșec la nivelul mașinii virtuale:
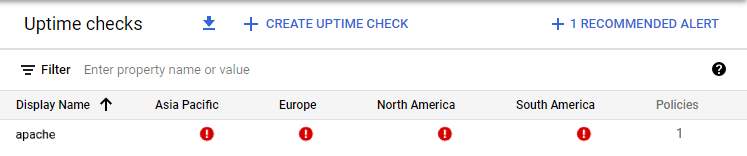
Uptime check view:

2. Mașină virtuală parțial funcțională:
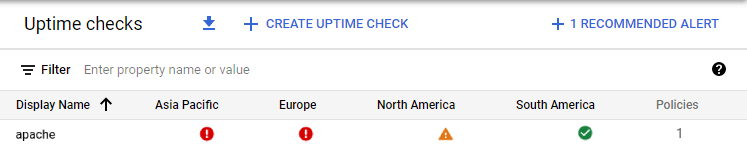
3. Mașină virtuală complet funcțională:
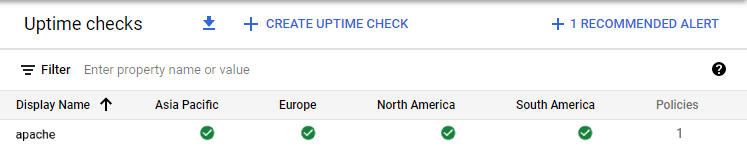
Uptime check view:
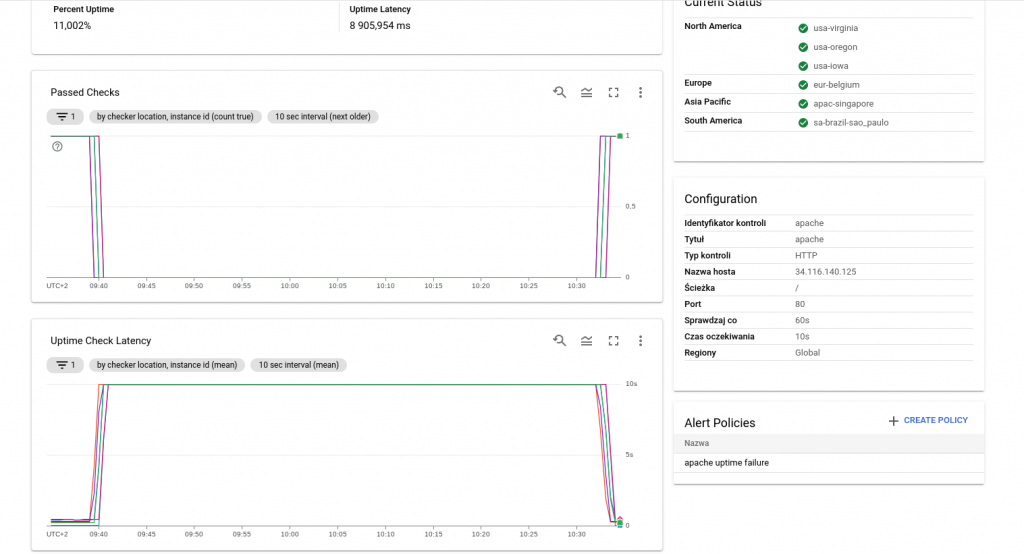
Alerte
Graficele sunt extrem de utile, însă sunt puțini angajați care au timp să observe schimbările 24/7. Dacă doriți să fiți informat în mod continuu despre anomalii (ex. defecțiunea serverului, atingerea unui anumit nivel de capacitate sau debit sau apropierea de pragul de facturare), ar trebui să creați politici de alertă care să trimită notificări atunci când sunt îndeplinite aceste condiții. Puteți primi notificarea printr-un canal selectat – de ex. SMS, e-mail, Slack sau PagerDuty.
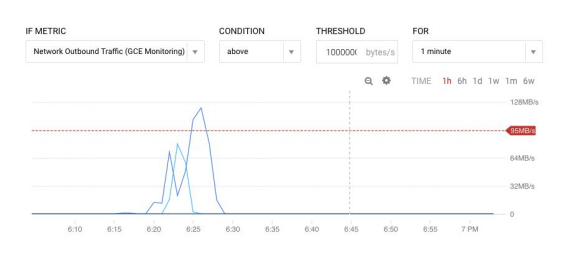
Cum să creați o alertă
Iată un exemplu despre cum se creează alertele de notificare. Pentru a crea o alertă, selectați Monitoring > Alerting din meniul din dreapta, apoi faceți clic pe Create policy.

Pe ecran va fi afișată o fereastră de configurare a politicii.
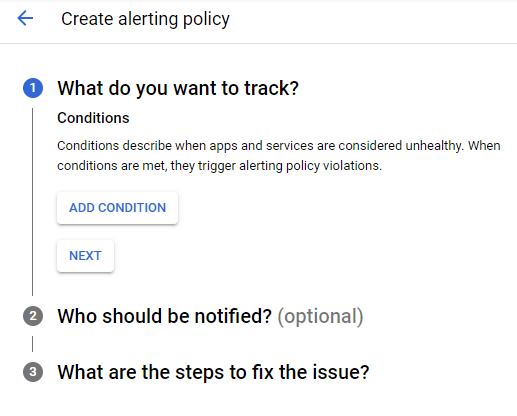
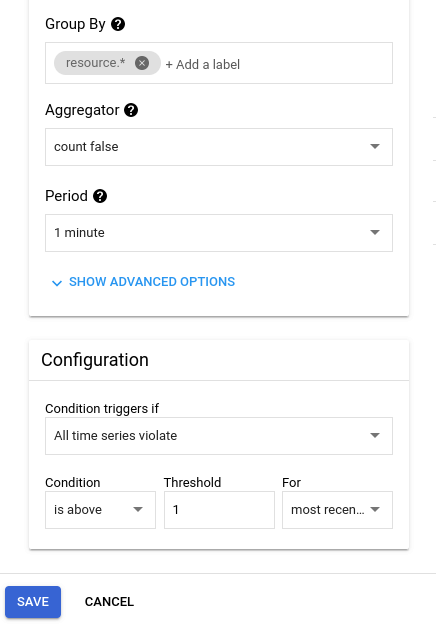
Creați o condiție făcând clic pe Add condition.

Creați o valoare – măsura pentru mașina virtuală.
Selectați Uptime Check URL.
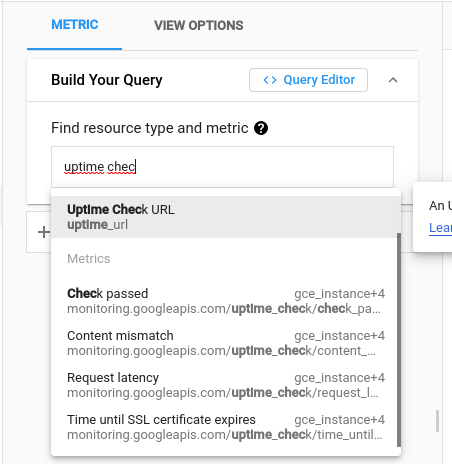
Pentru a verifica dacă instanța funcționează, selectați Check passed.

Ca filtru, adăugați controlul de accesibilitate creat – Apache.
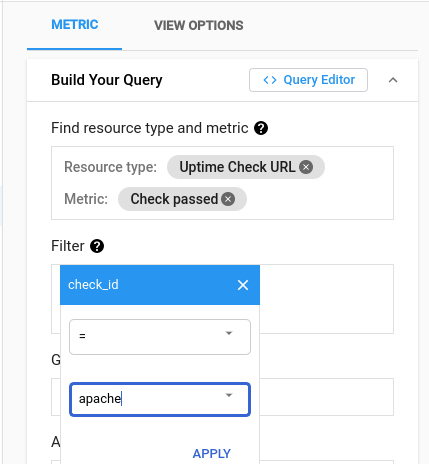
Consultați-vă proiectele.
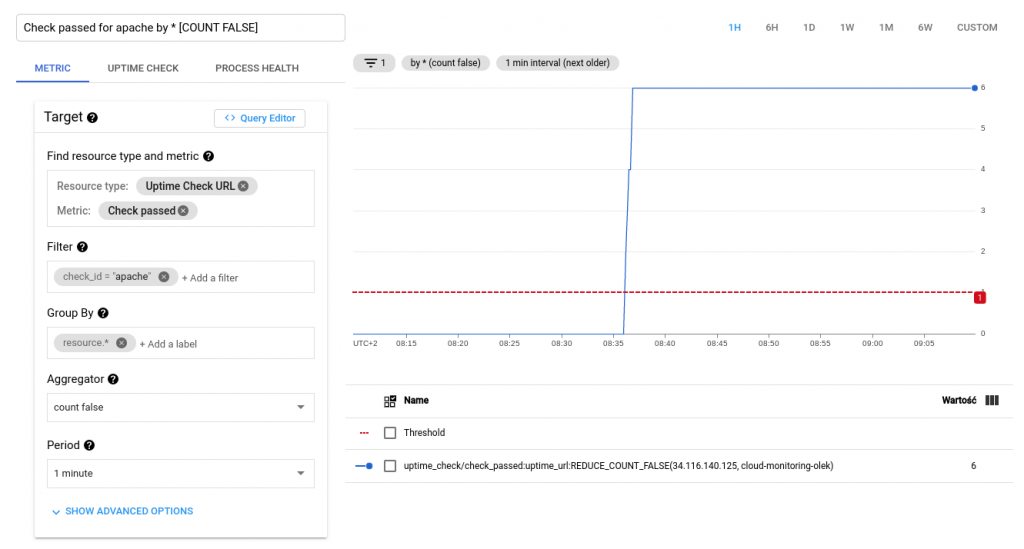
Pentru ca alerta de mai sus să fie setată, mașina virtuală trebuie să fie oprită timp de cel puțin un minut.
Notificări
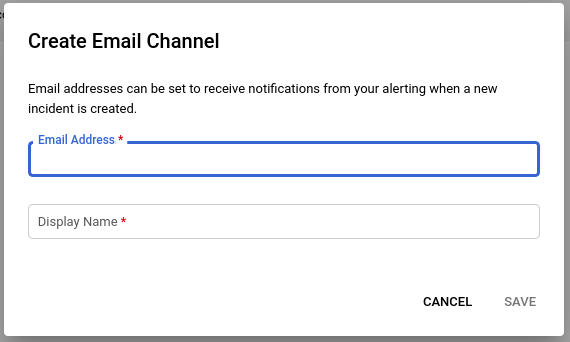
Pentru a fi informat când apare o problemă, configurați canalele de notificare în mod corespunzător. Faceți clic pe Manage notification channels.

Apoi selectați și configurați canalele prin care vor fi trimise aceste notificări. Pentru a utiliza un anumit canal, dați clic pe Add new.

Va fi afișată o fereastră în care puteți configura canalul selectat, de ex. prin email:
Odată configurate, canalele vor apărea sub formă de listă.

Putem adăuga, de asemenea, documentația adecvată alertei pentru a clarifica pașii care trebuie făcuți pentru o anumită defecțiune.

Mai jos este un exemplu de notificare prin e-mail:
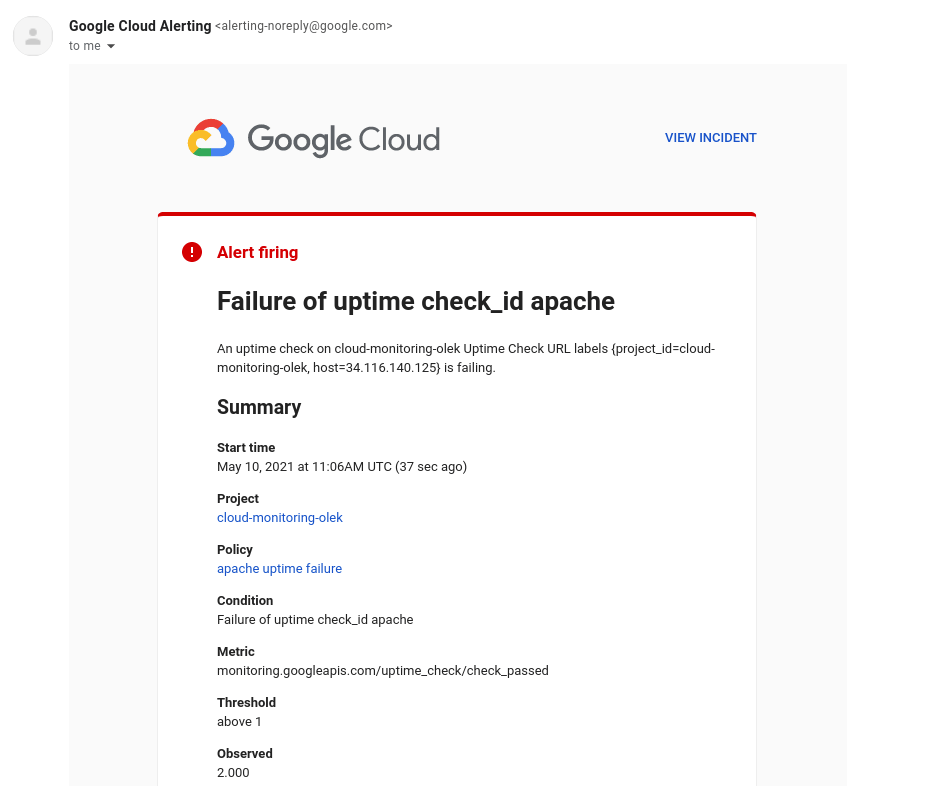
Dintr-un astfel de e-mail, puteți accesa direct consola Google Cloud făcând clic pe View incident. Se va deschide o fereastră cu detalii despre defecțiune:
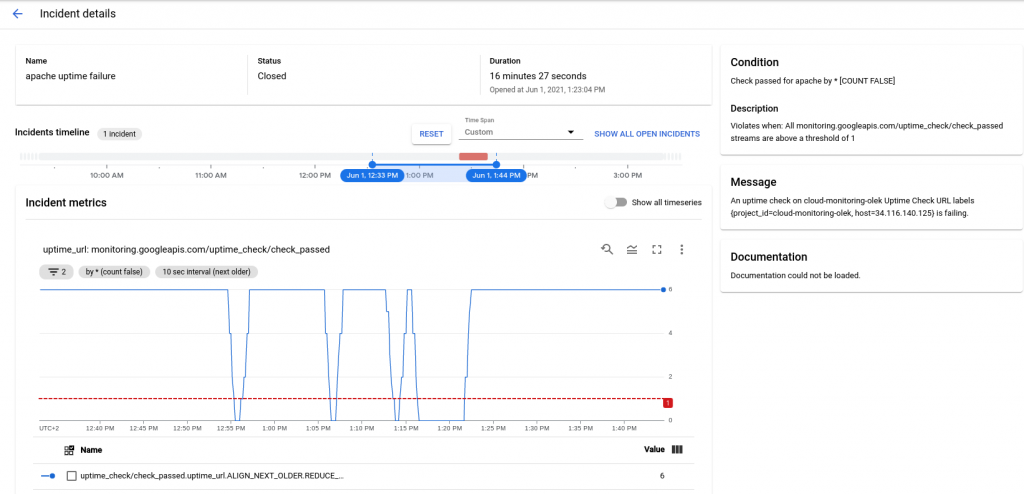
De asemenea, puteți crea alerte și selecta canale folosind API-ul. Pentru mai multe informații, consultați documentația Google Cloud.
Sfaturi și bune practici pentru crearea alertelor
- O recomandare este completarea alertei cu instrucțiuni, informații despre resursele care trebuie verificate și link-uri către documentația necesară. Acest lucru va permite ca incidentul să fie rezolvat mai rapid, chiar și de către o persoană care se întâlnește prima dată cu o astfel de situație.
- Este recomandat să monitorizați simptomele și nu cauzele. De exemplu, puteți seta o alertă pentru interogările eșuate la baza de date. Ăn cazul unui incident, puteți verifica dacă baza de date este inactivă.
- Ar trebui să vă asigurați că utilizați mai multe canale de notificare în același timp, de exemplu e-mail și SMS. Acest lucru vă va fi de folos când unul dintre canale eșuează.
- De asemenea, este important să evitați trimiterea prea multor notificări. Prea multe alerte pot determina persoanele care le primesc să le ignore. Alertele de monitorizare sunt menite să fie utile și adaptate în consecință.
Consultați un expert
Dacă doriți să fiți sigur că profitați din plin de puterea Cloud Monitoring, contactați experții cloud FOTC. Vă vom pune în legătură cu arhitecți certificați Google Cloud, care vă vor sfătui pas cu pas prin acest proces și vă vor răspunde la orice întrebare se ivește.