Spis treści
Infrastruktura jest sercem wielu współczesnych biznesów – zwłaszcza tych, które rozwijają i oferują produkty cyfrowe. Na pojęcie “infrastruktury” składa się gros elementów: serwery, maszyny wirtualne, dyski, bazy danych, sieci, usługi chmury obliczeniowej…
Te same organizacje, by zapewnić dostępność i stabilność produktów, a jednocześnie utrzymać wysokie tempo rozwoju, muszą monitorować każdy obszar infrastruktury, szybko reagować na awarie, a najlepiej namierzać potencjalne incydenty i zagrożenia jeszcze przed ich wystąpieniem.
Tutaj wkracza Cloud Monitoring – usługa Google Cloud Platform, która pozwala monitorować każdy element infrastruktury, nawet w modelu multi- czy hybrid cloud.
Czytaj też: Co to jest Google Cloud Platform i w jaki sposób wspiera biznes?
Co to jest Google Cloud Monitoring?
Cloud Monitoring to usługa chmury Google, która prowadzi pomiary usług Google Cloud Platform, jak też infrastruktury multi-cloud (w połączeniu GCP+AWS) czy hybrid cloud (za pośrednictwem narzędzia BindPlane). Gromadzi informacje o kondycji usług i aplikacji, dostępności, wydajności i przedstawia je za pomocą list, dashboardów czy samodzielnie utworzonych wykresów. Pozwala tym samym uzyskać odpowiedzi na takie pytania jak:
- Czy uruchomione usługi i aplikacje są dostępne i działają sprawnie?
- Jakie jest obciążenie danej usługi?
- Jaki jest czas pracy danej usługi (uptime)?
- Czy witryna internetowa działa i czy odpowiada w prawidłowy sposób?
- Jaka jest wydajność usług, aplikacji, serwisów?
Obok przedstawienia wyników na grafach, Cloud Monitoring daje możliwość ustawienia dowolnych alertów. System powiadomień (oprócz działania w obszarze SMS-ów i maili) można zintegrować z zewnętrznym narzędziami, takimi jak Slack czy PagerDuty. Każde powiadomienie może być sprzężone z niezbędną dokumentacją i instrukcją postępowania w obliczu konkretnego incydentu.
Cloud Monitoring, zbierając informacje z każdego zakątka infrastruktury – również w modelu multi- czy hybrid cloud – oraz informując użytkowników o anomaliach, umożliwia implementację metod SRE używanych przez samo Google.
Czytaj też: Business Continuity Plan – czym jest i jak go stworzyć?
SRE – czym jest Site Reliability Engineering?
Site Reliability Engineering może być tłumaczone na język polski jako inżynieria niezawodności. SRE to koncepcja, która wspiera tworzenie skalowalnych i wysoce niezawodnych aplikacji czy programów. Pozwala znaleźć i utrzymać złoty środek pomiędzy wysoką prędkością rozwoju a stabilnością kolejnych udostępnianych elementów systemu. Działania SRE mają doprowadzić do minimalizacji występujących błędów i awarii, między innymi poprzez nieustanne prowadzenie monitoringu (oraz ulepszanie metod namierzania i zwalczania incydentów) czy automatyzację wykonywanych zadań.

Koncepcja Site Reliability Engineering została utworzona przez Benjamina Treynora Slossa (VP of Engineering w Google) w 2003 roku. Początkowo SRE było rozwijane właśnie w Google, jako projekt wewnętrzny. Umożliwiło gigantowi tworzenie, wdrażanie, monitorowanie i utrzymywanie jednych z największych systemów na świecie. Obecnie zespół SRE Google liczy ponad 2500 specjalistów, którzy 24/7 dbają o niezawodność usług i produktów takich jak Google Cloud, Search, Ads, Gmail, Android, YouTube czy App Engine.
Koncept SRE jest też obecny niemal w każdej firmie, która tworzy produkt IT i stawia na szybki oraz stabilny rozwój. Firmy te, w dużej mierze, podążają ścieżką, którą kilkanaście lat temu wydeptał zespół SRE z Benem Slossem na czele.
Cloud Monitoring a Stackdriver
Przez niektórych zestaw usług chmury Google do monitorowania usług i aplikacji czy śledzenia logów jest nazywany Stackdriver.
W 2020 roku Stackdriver został przemianowany na Google Cloud’s operations suite – pakiet narzędzi do śledzenia logów, analizy wydajności aplikacji i usług czy namierzania i zwalczania wąskich gardeł infrastrukturalnych, na który składają się: Cloud Logging, Cloud Monitoring, Cloud Trace, Cloud Debugger i Cloud Profiler.
Zmiana nie wydarzyła się jedynie w obszarze nazwy. Stackdriver był dość rozproszonym zestawem usług; natomiast Google Cloud’s operations suite to jeden panel, z poziomu którego można monitorować całą infrastrukturę, jak i konkretny jej wycinek. Cloud Monitoring było ostatnią zmigrowaną do panelu usługą, a w związku z przemianowaniem zestawu narzędzi zmieniono też wygląd UI na bardziej intuicyjny, poprawiono nawigację oraz dodano nowe funkcje.
Co można monitorować w Google Cloud Monitoring? Tutoriale
Jeśli utworzysz projekt w Google Cloud Platform, automatycznie otrzymasz możliwość uruchomienia w nim usługi Cloud Monitoring. Jeśli chcesz nadać dostęp innej osobie, zwróć uwagę, czy nadana rola obejmuje uprawnienia do edycji Cloud Monitoring. Więcej informacji o dostępach do usługi znajduje się tutaj: Authorization.
Cloud Monitoring umożliwia przeglądanie i zarządzanie metrykami dla projektów w następujący sposób:
- dla pojedynczego projektu GCP,
- dla wielu projektów GCP w obrębie organizacji,
- dla wielu projektów GCP w obrębie wielu organizacji,
- dla przynajmniej jednego projektu GCP i dowolnej liczby kont AWS,
- dla przynajmniej jednego projektu GCP i infrastruktury on-premise (poprzez narzędzie BindPlane).
Pomożemy Ci uruchomić i wyjaśnimy jak działa Cloud Monitoring
Uruchomienie usługi Cloud Monitoring
Żeby przejść do usługi, trzeba być zalogowanym w konsoli Google Cloud Platform oraz mieć wskazany projekt, dla którego ma być utworzony monitoring.
W celu uruchomienia usługi należy z menu po lewej stronie wybrać Monitoring.
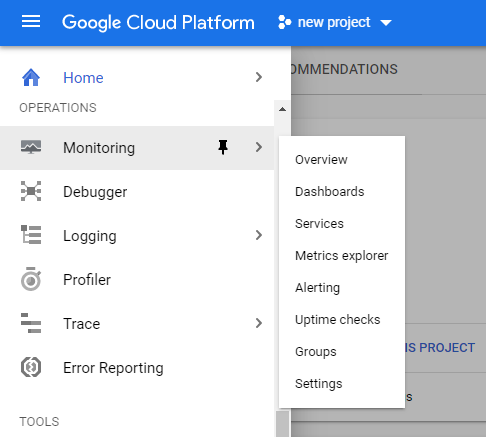
Po kliknięciu zostanie automatycznie utworzony panel z podsumowaniem dla danego projektu.

W panelu znajduje się komplet informacji – dashboardy, powiadomienia czy kontrole dostępności, pozwalające ocenić kondycję używanej w projekcie infrastruktury i najważniejszych jej elementów:
- w tabeli po lewej (Resources dashboard) znajduje się lista monitorowanych zasobów,
- niżej (Uptime checks) będzie znajdował się spis utworzonych reguł kontroli dostępności oraz ich wyniki z podziałem na lokalizacje,
- na dole (Groups) będzie lista pogrupowanych zasobów, z ostrzeżeniami dotyczącymi poszczególnych zbiorów,
- po prawej stronie (Incidents) znajduje się dashboard, w którym zapisane będą bieżące i zamknięte incydenty – czyli wydarzenia, które wyszły poza ustalone normy i wywołały alert,
- dalej (Charts) przedstawione są wykresy z informacjami dotyczącymi monitorowanych w projekcie usług.
Z panelu można też przejść do usługi przeglądania logów Logging czy Trace – usługi śledzenia opóźnień i namierzania bottleneck’ów.
Jeśli chcesz śledzić więcej niż jeden projekt, powinieneś utworzyć multi-project metrics scope – zakres metryk obejmujący kilka projektów. Tutaj znajdziesz informacje, jak utworzyć taki scope: Viewing metrics for multiple projects.
Instalacja agenta monitoringu
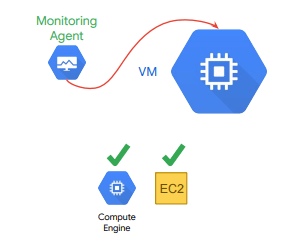
Cloud Monitoring może uzyskać dostęp do niektórych metryk używanych maszyn wirtualnych (CPU, ruch na dysku, ruch sieciowy, informacje o dostępności) bez “pośrednictwa” agenta. Jednak aby uzyskać dostęp do dodatkowych zasobów systemowych i usług aplikacji, należy zainstalować agenta monitorowania – Monitoring Agent.
Monitoring Agent zbiera metryki z maszyn w usłudze Compute Engine (GCP) oraz Amazon Elastic Compute Cloud (AWS).
Żeby zainstalować agenta monitorowania, w skrypcie startowym należy zawrzeć poniższe polecenia:
curl -sSO https://dl.google.com/cloudagents/add-monitoring-agent-repo.sh
sudo bash add-monitoring-agent-repo.sh
sudo apt-get update
sudo apt-get install stackdriver-agent
Więcej informacji o instalacji znajduje się tu: https://cloud.google.com/monitoring/agent/installation
Warto rozważyć też zainstalowanie agenta logów (Logging Agent), co da bardziej szczegółowy wgląd w akcje i kondycję maszyn wirtualnych. Tutaj znajduje sie więcej informacji o agencie logów: https://cloud.google.com/logging/docs/agent/logging.
Uptime checks – reguły kontroli dostępności
Kontrole dostępności (uptime checks) to żądania wysyłane do zasobów w celu sprawdzenia, czy odpowiadają – czyli czy funkcjonują prawidłowo.
Za pomocą uptime check można zweryfikować dostępność usług publicznych w lokalizacjach na całym świecie. Cloud Monitoring daje opcję sprawdzenia stanu aplikacji App Engine, adresu URL hosta, instancji Compute Engine, instancji AWS czy Elastic Load Balancer (systemu równoważenia obciążenia chmury Amazon). W konfiguracji uptime check należy wskazać protokół sieciowy – HTTP, HTTPS lub TCP. Dla każdej reguły można stworzyć politykę alertów i wyświetlić informacje o czasie między wysłaniem żądania a otrzymaniem odpowiedzi każdej z lokalizacji.
Aby utworzyć kontrolę dostępności, należy wybrać w menu Monitoring, następnie Uptime check i nacisnąć Create uptime check (u góry ekranu).
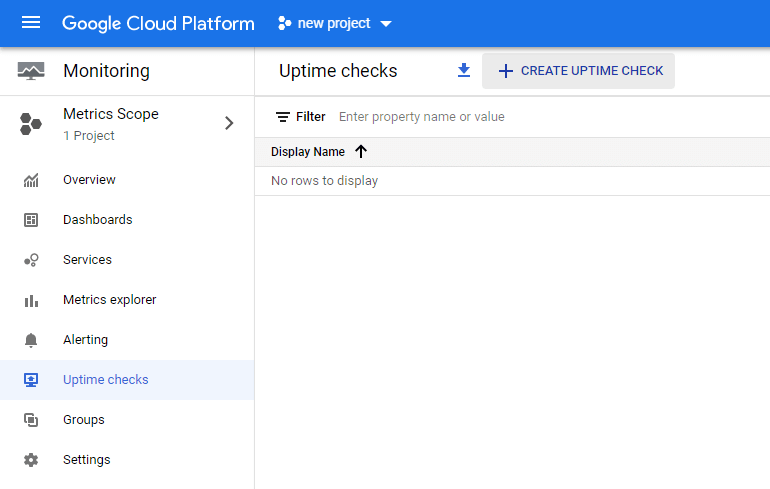
Pojawi się okno, w którym utworzymy regułę kontroli dostępności spełniającą wskazane warunki.
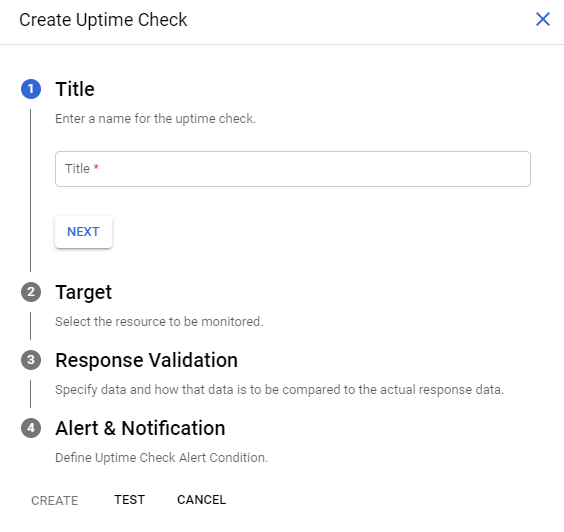
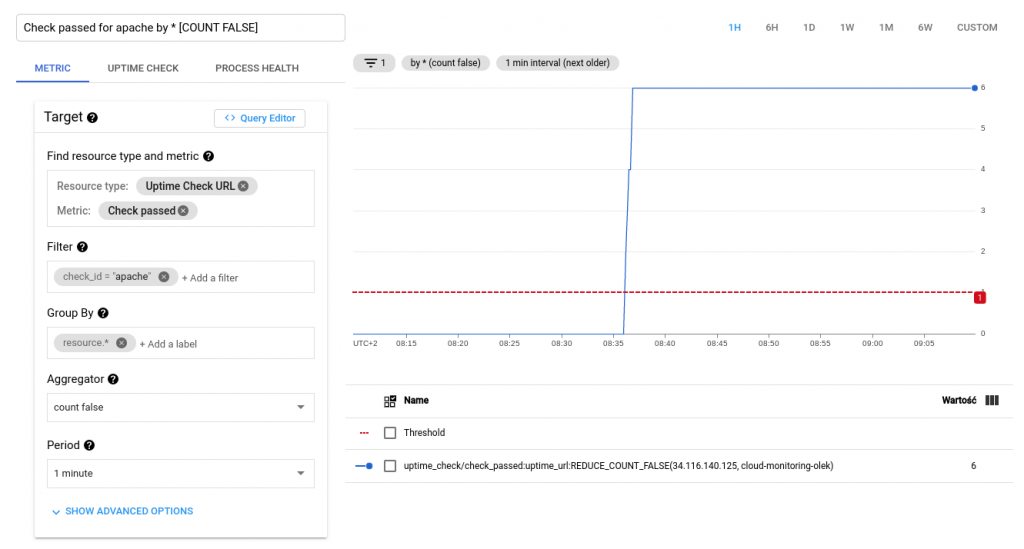
Przykładowy uptime check
Przedstawiony poniżej przykład sprawdza dostępność HTTP. Zasób jest sprawdzany co minutę z 10-sekundowym limitem czasu. Uptime checks, które nie dają odpowiedzi w ramach tego limitu, są uznawane za awarię.
Poniżej znajdują się przykłady, jak mogą wyglądać statusy widoczne w głównym panelu Uptime checks oraz w szczegółowych panelach.
1. Awaria maszyny wirtualnej:
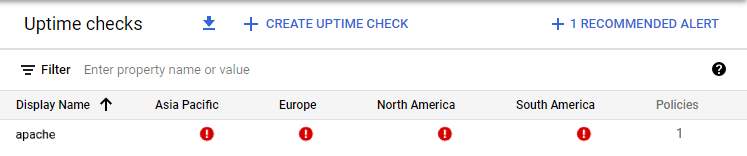

2. Częściowo funkcjonująca maszyna wirtualna:
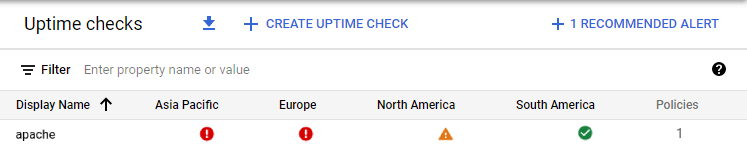
3. Sprawnie funkcjonująca maszyna wirtualna:
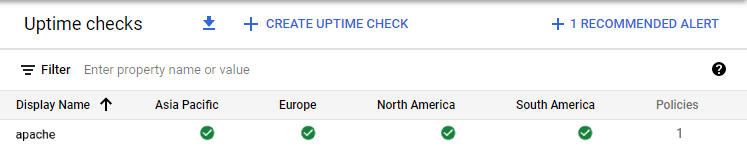
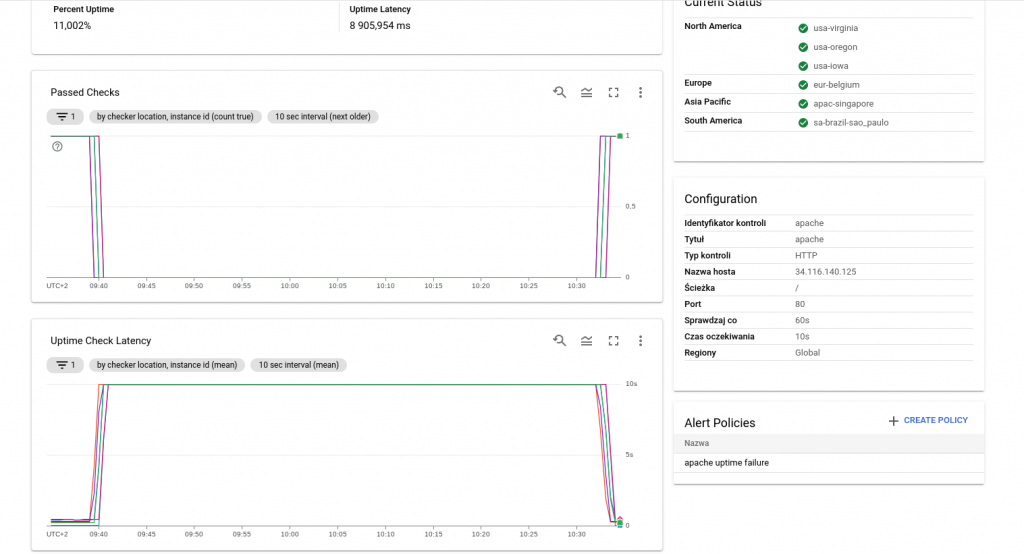
Alerty
Wykresy są niezwykle przydatne, ale mało kto ma czas, by obserwować zachodzące na nich zmiany 24/7. Jeśli chcemy być informowani na bieżąco o anomaliach (na przykład o awarii serwera, osiągnięciu konkretnego poziomu pojemności, przepustowości czy też o zbliżaniu się do progu rozliczeniowego) powinniśmy utworzyć polityki alertów, które wyślą powiadomienie w momencie, gdy spełnione zostaną konkretne warunki. Powiadomienie można otrzymać wybranym kanałem – np. SMS-em, na maila, na Slack czy PagerDuty.
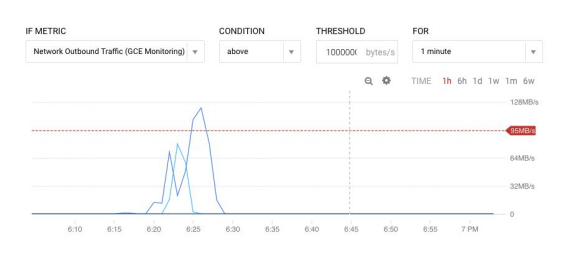
Tworzenie alertu
Oto przykład, jak wygląda tworzenie reguł powiadomienia. Aby utworzyć alert, musimy z menu po prawej wybrać Monitoring > Alerting, a następnie kliknąć Create Policy.

Pojawi się okno konfiguracji polityki.
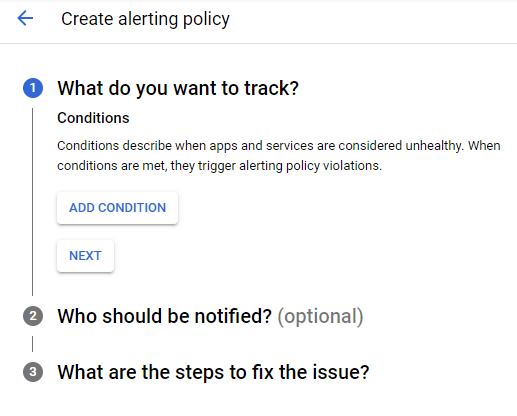
Tworzymy warunek, klikając add condition.

Tworzymy metrykę. W naszym przypadku będzie to metryka dla maszyny wirtualnej.
Wybieramy Uptime Check URL.
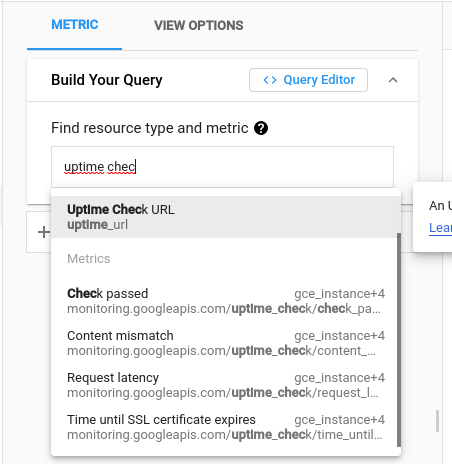
Żeby sprawdzić, czy instancja działa, wybieramy Check passed.

Jako filtr dodajemy utworzoną kontrolę dostępności – apache.
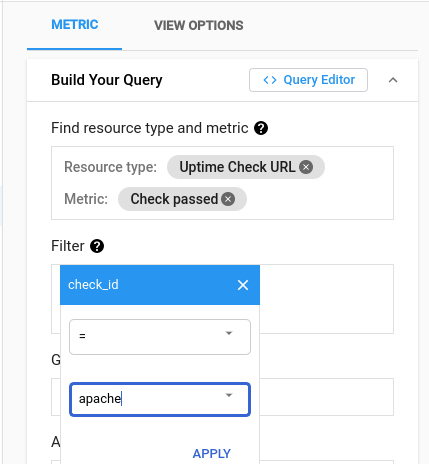
Odwołujemy się do naszych projektów.
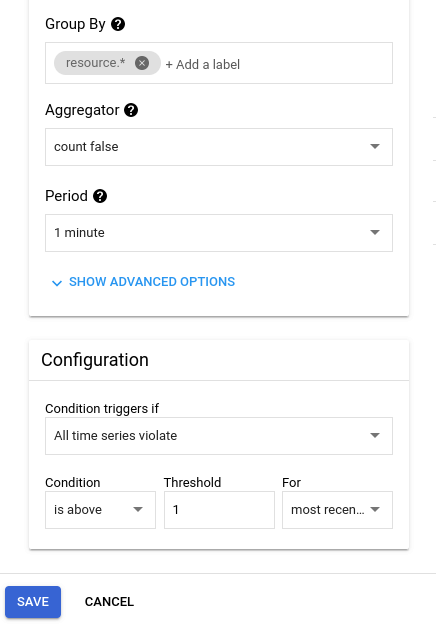
Aby powyższy alert zadziałał, maszyna wirtualna musi być wyłączona przez co najmniej minutę.
Zapewne chcielibyśmy otrzymać informację w momencie, gdy wystąpi problem. Dlatego musimy również w odpowiedni sposób skonfigurować kanały powiadomień. Klikamy Manage notification channels.

Zostaniemy przeniesieni do okna, w którym będziemy mogli wybrać i skonfigurować kanały, którymi mają być przesyłane powiadomienia. Aby skorzystać z konkretnego kanału należy kliknąć Add new.

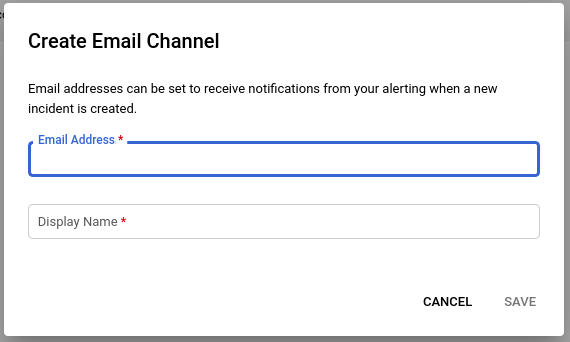
Pojawi się okno, w którym skonfigurujemy wybrany kanał.
Tak wygląda okno konfiguracji kanału email:
A tak kanału SMS:

W przypadku kanału SMS musimy zweryfikować poprawność wprowadzonego numeru poprzez przepisanie otrzymanego kodu.

Po skonfigurowaniu, kanały pojawią się na liście.

Po konfiguracji kanałów powiadomień wracamy do ustawień powiadomień i klikamy “odśwież”. Dzięki temu pojawią się nowe kanały, które dodamy do alertu.

Możemy też do alertu dodać odpowiednią dokumentację, by było jasne, jak postępować w przypadku konkretnej awarii.

Poniżej przykładowe powiadomienie mailowe:
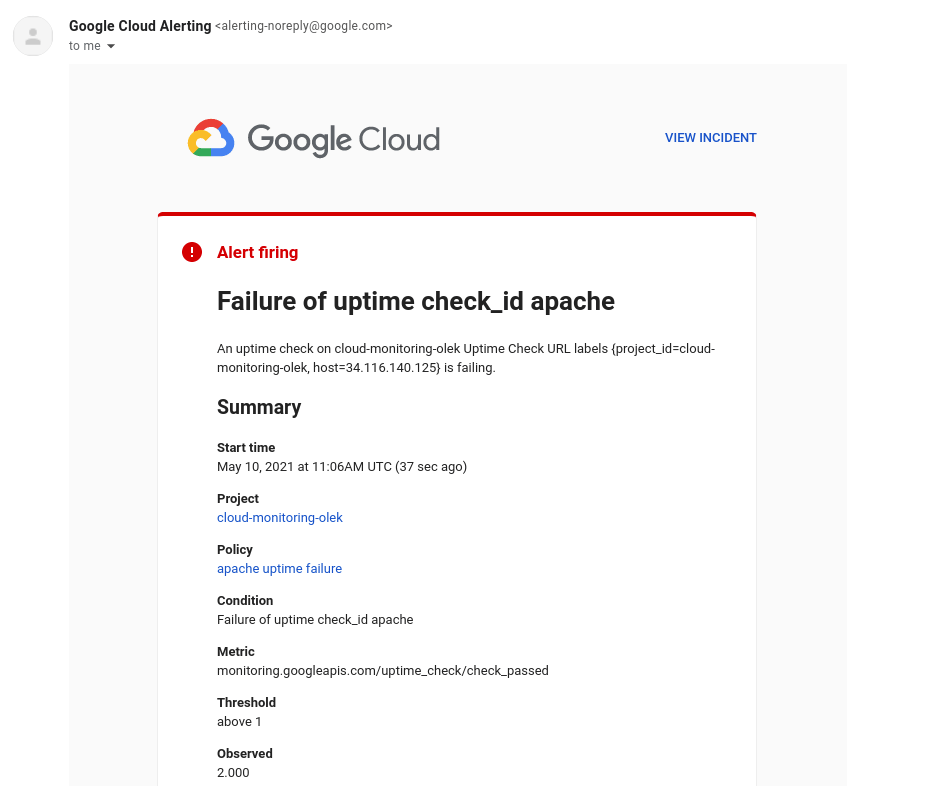
Z poziomu takiego maila mamy możliwość przejść bezpośrednio do konsoli GCP, klikając w View incident. Otworzy się okno ze szczegółami awarii:
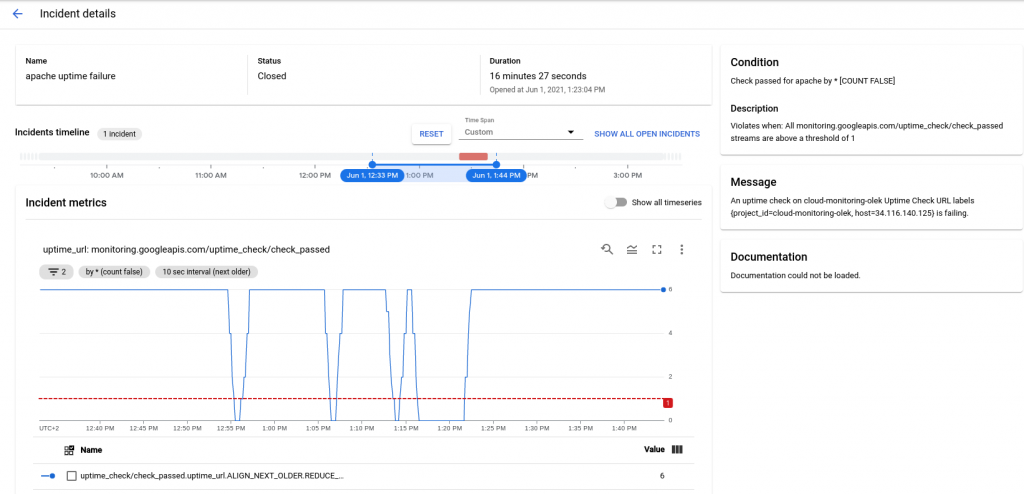
Mamy również możliwość tworzenia alertów i wyboru kanałów przy użyciu API. Więcej informacji znajduje się w dokumentacji Google Cloud:
Możemy również utworzyć zasadę wyzwalania alertu w sytuacji, gdy miesięczna suma bajtów dziennika logów przekroczy poziom zdefiniowany w usłudze Cloud Logging. Aby utworzyć taką politykę, można posłużyć się ustawieniami przedstawionymi poniżej:

Rady dotyczące tworzenia alertów
- Dobrze jest uzupełnić alert o instrukcje postępowania, informację, które zasoby należy zweryfikować czy niezbędną dokumentację. Pozwoli to szybciej zażegnać incydent, nawet przez osobę, która ma z nim pierwszy raz do czynienia.
- Zalecane jest monitorowanie objawów, nie przyczyn. Przykładowo, można ustawić alert na zakończone niepowodzeniem zapytania bazy danych, a w sytuacji incydentu sprawdzić, czy baza danych nie działa.
- Należy upewnić się, że korzystamy jednocześnie z kilku kanałów powiadomień, na przykład maila i SMS. Pozwoli to uniknąć sytuacji, w której jeden z kanałów zawiedzie.
- Ważne jest też unikanie nadmiaru wysyłanych powiadomień. Nadmierna liczba alertów może spowodować, że osoby, które je otrzymują, zaczną je ignorować. Alerty monitorowania mają być przydatne i odpowiednio dostosowane. Konfigurowanie alertów na bardzo szczegółowym poziomie, w mało istotnych obszarach nie jest dobrą praktyką.
Niestandardowe metryki
Jeśli standardowe metryki dostarczane przez Cloud Monitoring nie odpowiadają Twoim potrzebom, możesz utworzyć niestandardowe metryki dla następujących zasobów:
- instancje Amazon EC2,
- Dataflow job
- instancje App Engine,
- instancje Compute Engine,
- node obliczeniowy lub węzeł obliczeniowy,
- zadanie (task) zdefiniowane przez użytkownika,
- instancja kontenera GKE,
- klaster Kubernetes,
- kontener Kubernetes,
- node Kubernetes,
- pod Kubernetes.

Dla przykładu: weźmy serwer gier, który mieści 50 użytkowników. Z perspektywy infrastruktury można rozważyć użycie wskaźnika obciążenia procesora lub obciążenia ruchu sieciowego jako wartości, które są w pewnym stopniu skorelowane z liczbą użytkowników. Ale dzięki niestandardowym metrykom można faktycznie przekazać aktualną liczbę użytkowników bezpośrednio z aplikacji do usługi Cloud Monitoring.
Więcej informacji:
- Pełna lista metryk z podziałem na produkty: Metrics list
- Tworzenie niestandardowych metryk: Creating custom metrics
Dashboardy i grafy
W Cloud Monitoring mamy możliwość tworzenia własnych dashboardów dla wartości, które chcemy monitorować – zarówno metryk domyślnie zbieranych przez usługę, za pośrednictwem agenta monitoringu, dane logów czy metryki niestandardowe. Na wykresach można przedstawić dane liczbowe lub zakresy; nie jest możliwe zaprezentowanie danych tekstowych.
Wykresy zapewniają wgląd w kondycję maszyn wirtualnych oraz ruch sieciowy pomiędzy instancjami. Przykładowo, możemy utworzyć wykresy, które będą przedstawiały informacje o poziomie wykorzystania procesora danej instancji, pakietów lub bajtów wysyłanych i odbieranych przez tę instancję czy porzuconych przez zaporę firewall. Korzystając z filtrów, otrzymamy widok na dane na bardziej szczegółowym poziomie.
Aby utworzyć dashboard, z menu po lewej wybieramy Monitoring > Dashboards. Po przejściu do panelu klikamy Create Dashboard.
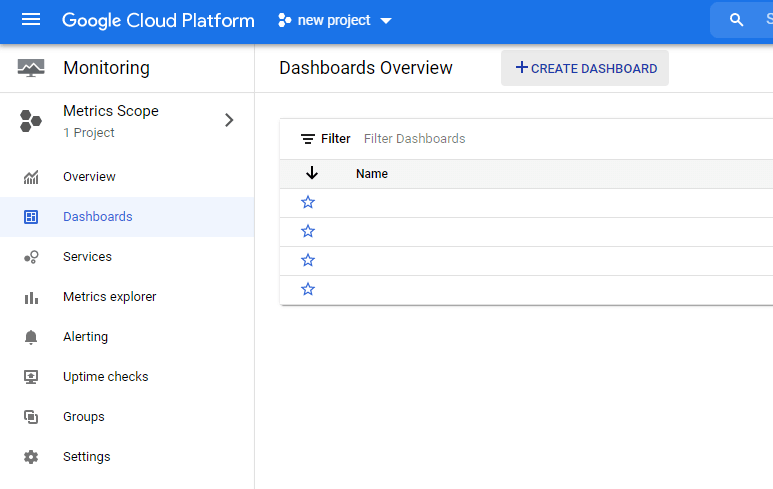
Zostaniemy przeniesieni do osobnego widoku, w którym nazwiemy panel i odpowiednio go zmodyfikujemy. Możemy wybierać spośród różnych rodzajów wykresów i modeli prezentacji danych (widoczne po lewej stronie screena poniżej).
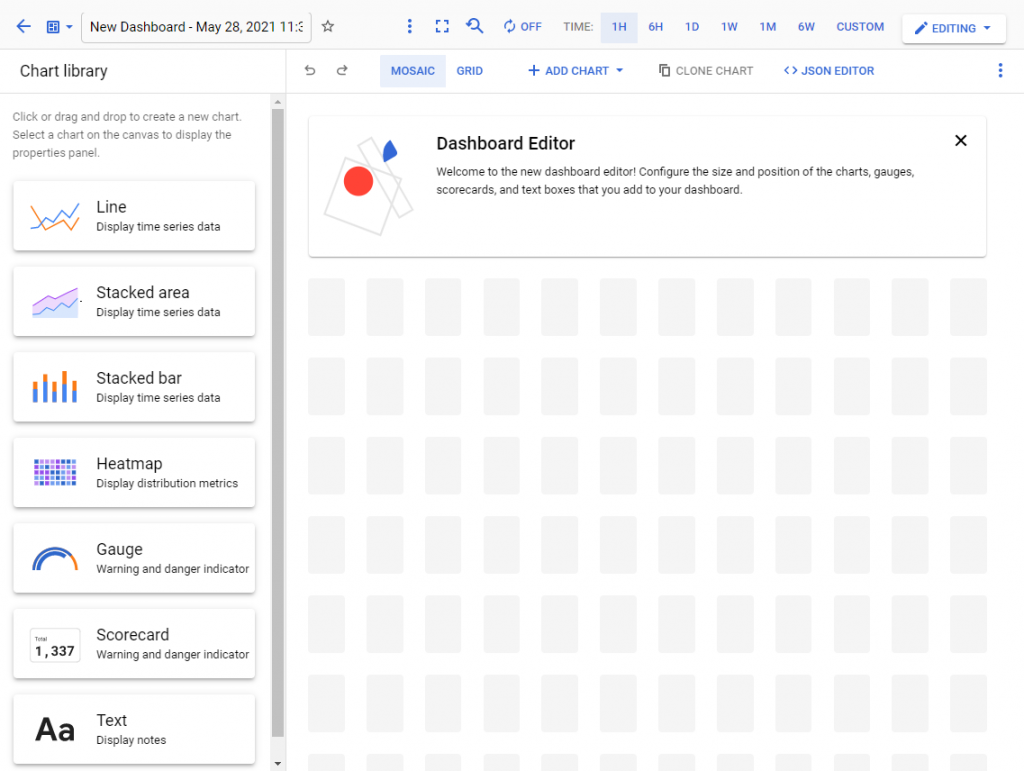
Aby dodać wykres, klikamy Add Chart i wybieramy sposób wyświetlania danych, który nas interesuje i który będziemy modyfikować w kolejnych krokach.
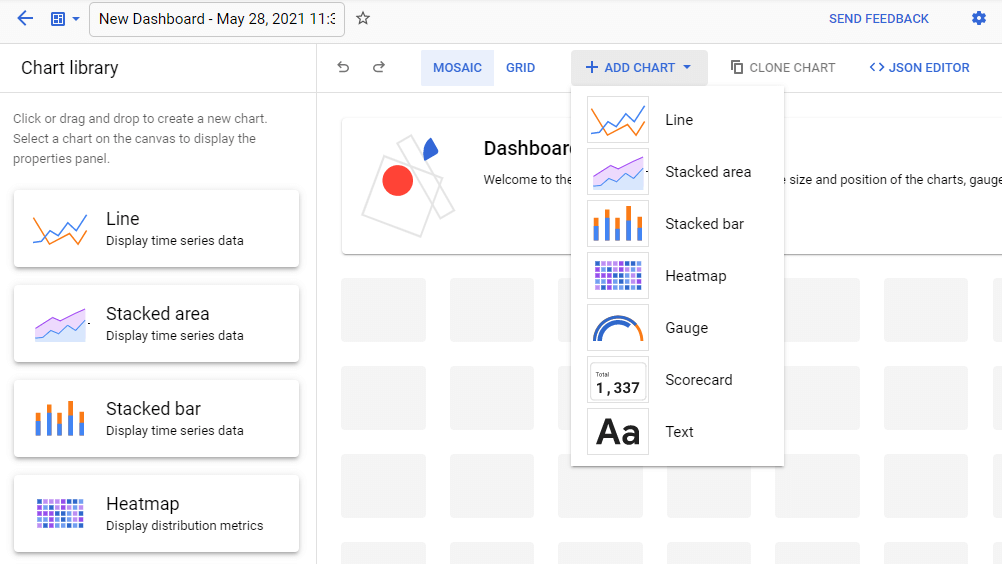
Wybieramy dane, które chcemy wyświetlić:

I mamy gotowy dashboard.
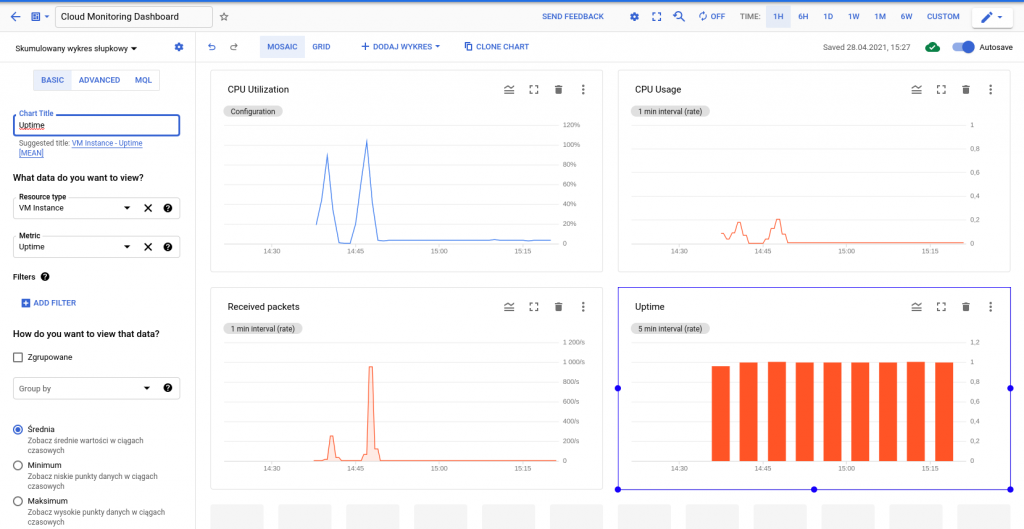
Wykresy będą widoczne w panelu Monitoring > Dashboards.
Powyżej pokazaliśmy dość szczegółowo sposób działania oraz konfiguracji Cloud Monitoring. Jeżeli jednak chcesz mieć pewność, że wykorzystujesz w pełni możliwości tej usługi, napisz do nas. Połączymy Cię z certyfikowanymi Google Cloud Artchitects, którzy pomogą przejść cały proces krok po kroku i odpowiedzą na Twoje pytania.
Zobacz też: