De la analize bazate pe comportamentului clienților și până la luarea de decizii în timp real, datele sunt o componentă esențială în activitatea și progresul oricărei companii. Cu toate acestea, extragerea, gestionarea și analiza cantităților mari de date poate fi o sarcină descurajantă. Aici intervine Google Cloud Dataflow, o soluție cloud fără server care revoluționează modul în care companiile procesează și analizează datele. În acest articol, analizăm avantajele și beneficiile Google Cloud Dataflow și explorăm modul în care acesta poate eficientiza modul în care efectuați operațiunile business, permițându-vă să valorificați întregul potențial al datelor generate de companie.
Ce este Dataflow? Prezentare generală a serviciilor
Dataflow este o soluție Google Cloud fără server, cu o latență foarte redusă, oferind o flexibilitate din punct de vedere al costurilor, securitate pentru fluxul de date și procesarea datelor în lot. Dataflow elimină nevoia de operațiuni complexe de întreținere prin automatizarea furnizării și scalării infrastructurii.
Datorită scalării pe orizontală și verticală, serviciul permite gestionarea sarcinilor sezoniere de lucru sau a perioadelor intense de trafic fără a vă încărca facturile. Dataflow permite companiilor să aibă o viziune de ansamblu asupra datelor, să dețină control deplin asupra proceselor de asimilare a datelor și să sporească viteza și performanța unui produs sau a unei aplicații.
Tehnic vorbind, Google Cloud Dataflow este un serviciu de pipeline de date care vă permite să implementați fluxul în pipeline-uri Apache, pe care le puteți crea folosind biblioteca Apache Beam.
Aprofundați lectura cu alte materiale:
Principalele caracteristici ale Dataflow:
- Limbaje de programare Dataflow – Google Dataflow acceptă limbaje de programare precum Python, Java și Go.
- Autoscalare verticală și orizontală care ajustează dinamic și la cerere capacitatea de calcul,
- Diagnosticare inteligentă care permite gestionarea datelor pe baza SLO (Service-Level Objective), opțiuni de vizualizare a lucrărilor și recomandări automate pentru îmbunătățirea performanței,
- Streaming Engine care mută părți ale execuției pipeline-ului în backend-ul serviciului, scăzând astfel latența datelor,
- Dataflow Shuffle care mută operațiunile de grupare și contopire a datelor de la VM în backend-ul Dataflow pentru loturi de pipelines care se scalează fără probleme,
- Dataflow SQL permite dezvoltarea pipeline-urilor Dataflow folosind limbajul SQL,
- Programarea flexibilă a resurselor (FlexRS) reduce costurile de procesare a loturilor mulțumită programării și contopirii VM-urilor,
- Șabloane Dataflow create pentru partajarea pipeline-urilor în întreaga organizație,
- Integrarea notebook-urilor care permite utilizatorului să creeze pipeline cu Vertex AI Notebooks și să le implementeze folosind Dataflow runner,
- Capturi cu modificările de date în timp real pentru sincronizarea și replicarea datelor cu o latență minimă,
- Monitorizare în linie care permite utilizatorului să acceseze valorile sarcinii pentru a ajuta la depanarea pipeline-urilor de loturi,
- Chei de criptare gestionate de client pentru a proteja pipeline-urile de loturi sau streaming cu CMEK,
- Dataflow VPC Service Controls, integrare cu VPS Service Controls pentru un nivel suplimentar de securitate,
- IP-urile private oferă o mai mare securitate pentru infrastructura de procesare a datelor și minimizează consumul întregului proiect Google Cloud.
Cum funcționează Dataflow?
În general, un pipeline de procesare de date implică trei pași. Datele sunt întâi citite direct de la sursă, apoi sunt transformate, pentru ca în final să fie rescrise sau procesate în lot. Această procesare în loturi este benefică companiilor, deoarece reprezintă un mijloc rentabil de a gestiona cantități mari de date simultan.
Datele sunt citite de la sursă într-o unitate numită PCollection, creată pentru a fi distribuită în numeroase mașini. Ulterior, acestea trec prin una sau mai multe operațiuni în acest stadiu, operațiuni cărora le vom spune transformări. De fiecare dată când este rulată o transformare, se va crea o nouă partiție PCollection. După ce sunt executate toate transformările, pipeline-ul scrie ultima PCollection într-o data sink.
Odată ce ați creat pipeline-ul, folosind Apache Beam în limbajul dorit, puteți folosi Dataflow pentru a iniția și executa pipeline-ul respectiv, identificat în acest punct ca o sarcină Dataflow. Urmăriți tutorialul următor pentru și mai multe explicații despre cum funcționează și cum se folosește Dataflow.
Subtipuri ale serviciului Dataflow
Google Cloud a creat trei subtipuri ale serviciului pentru diferite utilizări și pentru procesarea a mari volume de date:
- Dataflow Prime – un serviciu care scalează pe verticală (adăugând mai multe instanțe) și pe orizontală (creșterea specificațiilor mașinii sau prin adăugarea de memoriei pentru fluxurile de lucru de procesare a datelor. Dataflow Prime vă permite să creați pipeline-uri mai eficiente și să adăugați informații în timp real.
- Dataflow Go – un serviciu care oferă suport nativ pentru limbajul de programare Go, folosit pentru încărcăturile de lucru de procesare a datelor în loturi și în flux. Utilizează modelul multilingv al Apache Beam.
- Dataflow ML – un serviciu dedicat rulării modelelor PyTorch și scikit-learn direct în conductă. Permite implementarea modelelor ML cu puțin cod. Dataflow acceptă implementarea modelelor ML, inclusiv prin accesarea GPU-urilor sau sistemelor pentru a antrena modele, fie în mod direct, fie prin intermediul cadrelor precum Tensorflow Extended (TFX). Dataflow ML este o extensie pentru aceste funcționalități.
Deramați un proiect Google Cloud alături de FOTC
Când merită să utilizați serviciul Dataflow?
Dataflow este o opțiuni potrivită pentru aplicații care folosesc inteligența artificială în timp real, necesită depozitarea cantităților mari de date sau analiza acestora în flux.
În ce fel situații vă va ajuta Dataflow? Îl puteți folosi pentru cercetarea și segmentare în domeniu retail, clickstream sau analize la punctul de vânzare. Serviciul va ajuta, de asemenea, la detectarea fraudei în serviciile financiare, în personalizarea experienței pentru utilizatorii de jocuri și la analiza IoT în industrii precum producție și manufactură, asistență medicală sau logistică.
Unul dintre cei mai cunoscuți clienți care folosesc Dataflow este Renault. Încă din 2016, constructorul francez de mașini a început o transformare digitală ca parte a alinierii sale cu Industry 4.0, care a dus la implementarea infrastructurii Google Cloud în companie. De atunci, serviciul Dataflow a devenit instrumentul principal pentru majoritatea nevoilor de procesare a datelor în platformă. Drept urmare, Renault folosește Dataflow pentru a extrage și transforma rapid date din site-urile de producție și din alte puncte cheie.
Citiți mai multe:
Cât costă Dataflow?
La fel ca majoritatea serviciilor din Google Cloud, Dataflow funcționează și pe un model de plată pe măsură ce utilizați (pay-as-you-go). Vor fi facturate exclusiv resursele pe care le consumă sarcinile companiei și anume: regiunea în care rulează joburile, tipul de instanță VM, CPU pe oră, memoria pe oră sau volumul de date procesate.
Tariful de stabilire a prețurilor se bazează pe oră, dar utilizarea Dataflow este facturată în trepte de câte o secundă pe baza încărcării. Când Dataflow se intersectează cu alte servicii, cum ar fi Cloud Storage sau Pub/Sub, costurile acestor servicii se vor aplica separat.
Una dintre caracteristicile de stabilire a prețurilor Dataflow este Flexible Resource Scheduling (FlexRS). Acesta combină mașini virtuale într-un singur pool Dataflow, asigurând costuri de procesare mai mici.
Mai jos, găsiți exemple de prețuri Dataflow facturate pentru o oră de utilizare, pentru regiunea Londra (europe-wst2), cu configurații de instanță:
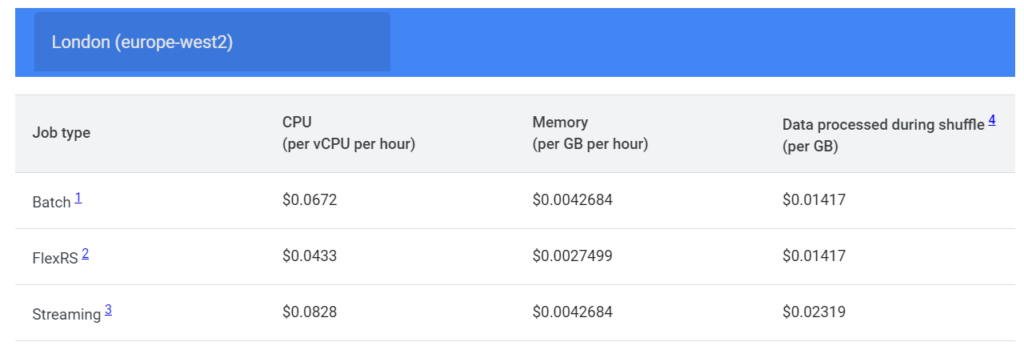
Google vă pune la dispoziție un calculator de prețuri pentru a ajuta la estimarea costurilor, dar datorită numărului mare de variabile, costul Dataflow va fi specific oricărui caz particular de utilizare.