Scena business este în schimbare rapidă, iar companiile sunt mai vulnerabile ca niciodată la întreruperi neașteptate. Operațiunile nenumăratelor afaceri se bazează pe disponibilitatea sistemelor IT – de la un flux continuu de lucru la flexibilitate și, totodată, o dependență totală de tehnologiei a acestora. De aceea, este esențial să existe un plan cuprinzător de recuperare în caz de dezastru pentru orice afacere care dorește să minimizeze impactul unor astfel de evenimente.
Potrivit studiilor, costul mediu al unui minut de nefuncționare a unei întreprinderi mari este între 5.600 USD și 9.000 USD (Gartner, Institutul Ponemon). În cazul întreprinderilor mici și mijlocii, costul unui minut de oprire a sistemului variază de la 137 la 427 USD (Carbonit). O întrerupere de 13 minute a Amazon.com în 2015 a costat compania peste 2,5 milioane de dolari. Și aceste date se referă doar la timpul de nefuncționare în furnizarea serviciilor – nu pierderi de sistem sau de informații și costurile restaurării acestora.
Fiecare minut de indisponibilitate a sistemului se traduce prin tot mai multe pierderi financiare. De aceea, este atât de important să ne asigurăm că datele și toate elementele esențiale ale unei aplicații sunt sigure și securizate, să elaborăm un plan de gestionare a situațiilor neprevăzute și a crizelor și să instruim personalul în consecință pentru a putea restaura un website afectat în cel mai scurt timp posibil.
Mai departe, vom explora elementele cheie ale unui plan de recuperare în caz de dezastru și vă vom oferi sfaturi practice pentru crearea și implementarea unuia.
Pasul 1. Planul de continuitate a afacerii (business continuity plan)
Un plan de continuitate a afacerii face posibilă gestionarea eficientă a situațiilor de criză din domeniile cruciale și reducerea la minimum a efectelor negative cauzate de astfel de incidente. Un Business Continuity Plan (BCP) ar trebui să ia în considerare situații precum:
- un dezastru natural (cutremur, inundații),
- o defecțiune suferită de clădirea care găzduiește afacerea (inundație, incendiu, prăbușirea structurii),
- un accident de circulație sau transport (de exemplu, în cazul expeditorilor),
- furtul sau distrugerea documentelor fizice,
- furtul hardware-ului companiei sau a soluțiilor backup,
- piratarea sistemului IT.
BCP ar trebui să enumere toate domeniile de importanță crucială pentru activitatea companiei. Aici intră păstrarea documentelor fizice intacte, întreținerea clădirii în care se află sediul sau arhiva companiei și menținerea angajaților în siguranță în fața unui dezastru.
Citește mai multe despre dezvoltarea unui Business Continuity Plan:
Fiecare departament esențial al unei companii ar trebui să stabilească un proces detaliat de răspuns, inclusiv linii directoare de comunicare (de exemplu, cine trebuie anunțat primul în cazul unui incident – și în ce ordine) sau informații despre următorii pași care trebuie urmați. Instrucțiunile trebuie prezentate în cel mai clar mod posibil, iar personalul trebuie instruit pentru astfel de cazuri de urgență. Documentul în sine și copiile sale ar trebui să fie securizate și prezente în mai multe locații.
În cazul companiilor ale căror operațiuni de bază se bazează exclusiv pe tehnologie, un element obligatoriu în planurile de continuitate a afacerii este un plan de recuperare în caz de dezastru – un plan de acțiune care descrie pașii de urmat pentru a recupera sistemele și datele după o astfel de defecțiune.
Plan de recuperare în caz de dezastru (DRP)
Un plan de recuperare în caz de dezastru este un document care conține o descriere a procedurilor de urmat în cazul unui incident IT. Exemple de astfel de incidente pot avea loc la un centru de date propriu, la furnizorul de servicii, o defecțiune a aplicației, o eroare critică de sistem sau timp de nefuncţionare în disponibilitatea instrumentelor de lucru digitale.
Scopul unui astfel de plan este de a se asigura că o aplicație (întreagă sau doar părți cruciale din aceasta) reia funcționarea într-o manieră stabilă și restabilește accesul la date și posibilitatea de a procesa datele în continuare în cel mai scurt timp posibil. Un răspuns rapid și bine gândit scurtează timpul de nefuncționare a sistemului și atenuează impactul negativ al perioadei de nefuncționare.
De exemplu, să ne imaginăm că avem un lanț de magazine fizice și un site web de comerț electronic. Ar trebui să adoptăm măsuri de securitate în cazul unor evenimente precum:
- o eroare critică în producția destinată magazinului electronic,
- o întrerupere a sistemului Enterprise Resource Planning (ERP),
- un atac de hackeri, furtul sau scurgerea de date,
- o defecțiune a centrului de date care rezultă din indisponibilitatea site-ului web sau a sistemului ERP,
- o defecțiune a serverului de e-mail,
- o perioadă de nefuncționare a sistemului de servicii pentru clienți (provocată de furnizorul de servicii),
- defectarea unui terminal de plată sau a sistemului POS.
Dacă oricare dintre aceste situații este crucială pentru funcționarea afacerii noastre, ar trebui să luați în considerare aceste proceduri de recuperare în caz de dezastru.
RPO și RTO – cele mai importante valori ale unui plan de urgență
Un plan de recuperare în caz de dezastru ar trebui să includă două metrici importante – un obiectiv al punctului de recuperare și un obiectiv al timpului de recuperare. Disaster Recovery se concentrează pe ambele aceste valori de timp, exprimate de obicei în minute sau ore.
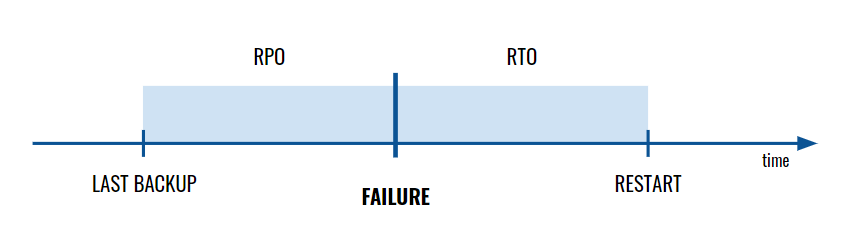
Obiectivul punctului de recuperare (RPO) este o valoare care descrie perioada de timp garantată de ultimul backup sau transfer de date către Centrul de recuperare în caz de dezastru. Dacă o aplicație este modificată semnificativ la fiecare câteva minute, RPO-ul ar trebui să dureze câteva minute. Dacă actualizările/modificările sunt mai puțin frecvente sau mai puțin critice, valoarea RPO poate ajunge chiar și la câteva ore.
Obiectivul de timp de recuperare (RTO) este o măsură care determină timpul maxim permis pentru a restabili funcționalitatea completă după un dezastru – adică durata maximă acceptată de nefuncționare a sistemului. RTO este adesea o componentă a unui acord privind nivelul de servicii (SLA), așa că determinarea valorii acestuia este esențială pentru obiective preum îndeplinirea termenilor contractului încheiat cu un client.
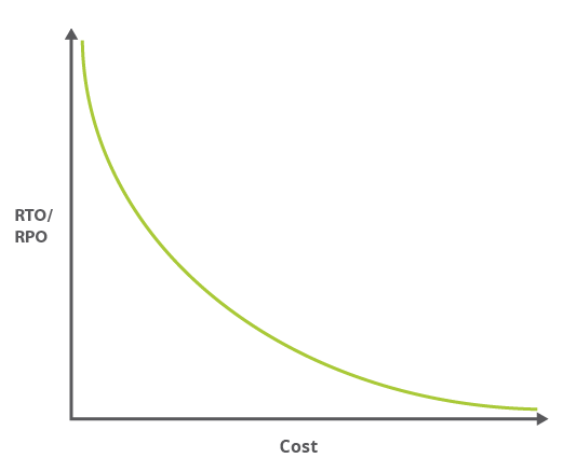
Cu cât sunt mai mici valorile obiectivului punctului de recuperare și ale obiectivului timpului de recuperare (cu cât intenționăm să restabilim mai repede cea mai recentă versiune a sistemului), cu atât costul restaurării după o defecțiune este mai mare.
Ce ar trebui să conțină un plan de recuperare în caz de dezastru?
Ce domenii trebuie acoperite și ce măsuri trebuie luate în fața unei crize? Fiecare companie va trebui să dea un răspuns individual, personalizat pentru fiecare sistem în sine.
Dar există câțiva pași universali de urmat atunci când se elaborează un plan de recuperare în caz de dezastru. Aceste metode de recuperare în caz de dezastru includ:
1. O listă cu hardware-ul și software-ul utilizat
Primul pas este să faceți un sondaj IT în companie – întocmirea unei liste cu produsele electronice și digitale în uz, esențiale pentru funcționarea companiei și predispuse la eșec.
O astfel de listă de teste regulate de recuperare în caz de dezastru ar trebui să includă, de exemplu:
- instrumentele utilizate și furnizate de furnizori terți (de exemplu, server de e-mail, aplicații de afaceri, sistem de ticketing),
- echipamentele fizice (de exemplu, dispozitive de stocare a datelor, calculatoare sau servere deținute de companie),
- activele virtuale închiriate (de exemplu, găzduire într-un cloud privat sau public),
- cele mai importante documente digitale și locul de stocare a acestora,
- elemente ale aplicației sau baze de date – cu indicarea locațiilor respective.
2. Evaluarea de tip criticitate a anumitor zone
Următorul pas este evaluarea nivelului de criticitate a anumitor elemente. Trebuie să identificăm zonele care vor avea de suferit în lipsa accesului la anumite informații sau instrumente și să stabilim impactul unei astfel de situații asupra continuității afacerii.
3. Evaluarea riscului și a impactului unui DRP asupra afacerii
Este important să se determine potențialele amenințări la adresa anumitor zone și să se ia în considerare consecințele pe care le implică acestea. Trebuie să luăm în considerare incidentele minore (de exemplu, o eroare de pagină care duce la câteva minute de întrerupere), precum și scenarii mai defavorabile (de exemplu, distrugerea completă a centrului de date împreună cu fișierele aplicației).
Este o idee bună să estimați valoarea financiară a anumitor elemente de acest tip. Există multe formule online pentru a calcula costul chiar și pentru un minut de oprire a sistemului.
Identificarea potențialelor incidente și a efectelor acestora face posibilă stabilirea unor obiective fezabile și adoptarea de indicatori realiști în următoarele etape ale dezvoltării planului.
4. Stabilirea obiectivelor de recuperare după dezastru
Cu o listă de elemente prioritare pregătită, este necesar să se determine RTO și RPO pentru zone individuale. Dacă un anumit element este critic, timpul pentru restaurarea celei mai recente versiuni ar trebui să fie cât mai scurt posibil. Obiectivele de recuperare ar trebui să fie însoțite de procese și strategii de recuperare în urma unor astfel de incidente. De exemplu, dacă o companie oferă numeroase servicii, ar trebui să se asigure că răspunsul din partea Centrului său de recuperare în caz de dezastru este cât mai rapid și eficient posibil.
5. Crearea unui document exhaustiv
Informațiile menționate mai sus – lista elementelor din aplicație, instrumentele și echipamentele utilizate împreună cu setarea unei priorități – ar trebui să fie scrise și încorporate într-un mod clar și ușor de înțeles într-un singur document. DRP ar trebui să fie un ghid destinat comunicării interne și externe, pentru cei identifică primii un incident, permițându-le să reacționeze rapid și într-un mod organizat.
Un plan de recuperare în caz de dezastru ar trebui să includă și:
- o listă a instrumentelor digitale utilizate și/sau a produselor proprii dezvoltate,
- o listă a echipamentelor fizice și a activelor virtuale în uz – cu indicarea furnizorului,
- o listă a angajaților responsabili pentru o anumită zonă,
- o listă cu detaliile persoanelor de contact care trebuie notificate cu privire la incident,
- un program de activități care trebuie întreprinse în cazul unui incident dat, care să includă o descriere a incidentului, o descriere a pierderilor, trimiterea notificărilor de întrerupere a serviciului către utilizatori, o indicație a pașilor de urmat pentru a readuce sistemul în funcțiune (de exemplu, calea către fișierul de rezervă sau un ghid despre cum să lansați Centrul pentru Recuperarea în caz de dezastru).
- o descriere a acțiunilor care trebuie întreprinse după pornirea sistemului, de ex. un test de încărcare, o analiză a situației care a avut loc sau o descriere a evenimentului.
6. Amplasarea DRP într-o locație sigură
Documentul și copiile sale trebuie să fie accesibile angajaților în mai multe locații. Un plan de recuperare în caz de dezastru nu ar trebui să fie niciodată localizat în același loc cu alte fișiere și date esențiale, deoarece, în cazul unui dezastru, veți pierde automat și accesul la el.
De exemplu, dacă aveți propriul centru de date, puteți păstra documentul DRP pe un alt server, aflat la distanță de acesta – sau în cloud.
7. Planificați testarea și îmbunătățiți constant planul
Următorul pas de făcut este testarea planului și a tuturor procedurilor aferente. Acest lucru va face posibilă revizuirea indicatorilor adoptați, identificarea zonelor de potențial pericol și îmbunătățirea planului în general.
Acest pas este foarte important – de multe ori veți înțelege ce trebuie modificat abia după o testare în practică. Testele vă vor indica, de asemenea, care sunt domeniile care necesită o pregătire a personalului mai accentuată.
8. Instruirea regulată a personalului și actualizări ale documentelor
Este important să proiectați și să desfășurați un program de formare specific companiei dvs. Instruirea ar trebui revizuită în mod regulat – la fel și Planul de recuperare în caz de dezastru.
Ce este centrul de backup și recuperare în caz de dezastru?
Un backup implică copierea elementelor esențiale ale unei aplicații – de ex. fișiere cu codul sursă, baze de date, documente electronice – și plasarea lor în altă locație. Dar această soluție poate să nu fie întotdeauna suficientă. Dacă pierdem accesul la infrastructură, restaurarea activelor dintr-un backup într-un mediu diferit poate dura de la câteva zeci de minute la câteva ore sau chiar zile. De asemenea, poate fi imposibil să recuperați toate datele – să presupunem că backupul are loc în fiecare zi la miezul nopții și site-ul nostru se blochează imediat după ora 23:00. Toate datele colectate în ultima zi sunt practic pierdute.
Un Centru de recuperare în caz de dezastru (Disaster Recovery Centre), la rândul său, este un centru de date de rezervă care funcționează 24/7. Este o locație distinctă și îndepărtată din punct de vedere geografic, cu o copie de rezervă a infrastructurii dvs. de afaceri, care se conectează cu infrastructura principală și stochează o copie a întregului sistem și a tuturor bazelor de date. Dacă există o defecțiune la centrul principal, traficul poate fi redirecționat către centrul de rezervă – atât de repede încât utilizatorii aplicației afectate nici nu vor sesiza efectele acesteia.
Există trei modele de centru de recuperare în caz de dezastru:
- Un centru de recuperare în caz de dezastru propriu de rezervă. Ar trebui să fie localizat suficient de departe geografic pentru a putea supraviețui unui potențial dezastru, dar în același timp bine conectat pentru a atinge o cât mai mare viteză de transfer a datelor. O astfel de soluție este costisitoare deoarece avem nevoie de două ori mai multe resurse (costuri de construcție și măsuri de securitate, echipamente fizice, specialiști) decât necesar pentru întreținerea centrului de date primar;
- Un centru de recuperare în caz de dezastru situat în afara sediului. Vorbim de un centru de date extern, deținut de un furnizor de servicii selectat. Furnizorul de servicii trebuie să garanteze standarde înalte în domeniul siguranței fizice a hardware-ului și a rețelei, stabilitatea conexiunii, viteză de transfer de date sau disponibilitatea serviciului. Costul „închirierii” unui DRC în afara sediului este adesea mai mic decât cel al înființării unui DRC propriu;
- Disaster Recovery as a Service (DRaaS) – un centru de date de rezervă în cloud. Serviciul DRaaS implică realizarea unei copii a întregului mediu de sistem pentru a fi stocată în cloud-ul furnizorului de servicii. Pornirea sistemului în modul de urgență este relativ rapidă și ușoară. Infrastructura este gestionată printr-o consolă de browser web, iar valoarea RTO poate fi chiar și de câteva minute.
Cooperați cu specialiști cloud pentru un plan de recuperare în caz de dezastru
Construiți un plan de recuperare în caz de dezastru în Google Cloud
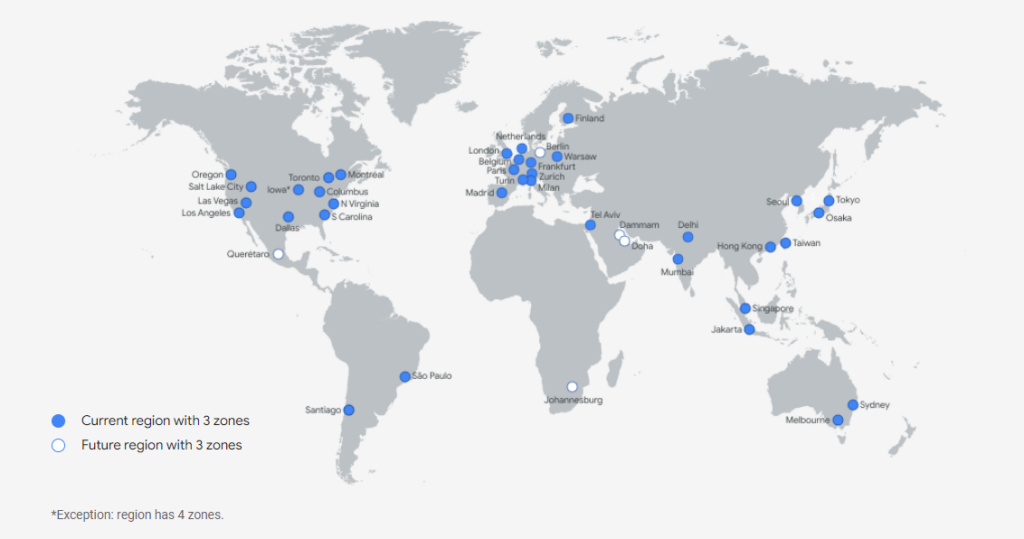
Google Cloud vă oferă disponibilitate a serviciilor de 99,95-99,99%, cu propria rețea de fibră optică care conectează peste 70 de centre de date din întreaga lume. Unele locații sunt grupate la nivel de regiuni pentru a garanta un nivel mai ridicat de disponibilitate a serviciilor în caz de defecțiuni sau dezastru. La rândul ei, o regiune este compusă din cel puțin trei zone, în care două acționează ca un centru de recuperare în caz de dezastru și mențin aplicația funcțională în cazul în care un centru de date este distrus.
Infrastructura Google susține recuperări rapide după un dezastru pe baza:
- unei rețele globale formată din sute de centre de date și zeci de mii de cabluri de fibră optică care conectează aceste centre,
- redundanței asigurată de numeroase PoP-uri (puncte de prezență) și copierii automate a datelor între dispozitive din diferite locații,
- scalabilității care face posibilă gestionarea unei sarcini de zeci de ori mai mare decât de obicei într-o fracțiune de secundă; în cazul multor servicii, scalabilitatea este un proces automatizat,
- măsuri de securitate fiabile, dezvoltate timp de 17 ani de o echipă de sute de specialiști în securitate cibernetică și infosec,
- respectarea reglementărilor și cerințelor legale, cum ar fi Certificările ISO 27001, SOC 2/3 sau PCI DSS 3.0.
Pe lângă disponibilitatea și performanța ridicată oferite de Google Cloud, un alt mare avantaj este suportul oferit de specialiști certificați. La nivel local, partenerii Google Cloud sunt capabili să sprijine organizațiile în dezvoltarea unui plan adecvat de recuperare în caz de dezastru și în pregătirea unui Centru de recuperare în caz de dezastru stabil în cloud-ul Google.
Arhitectura cloud Google: Zone și regiuni
Infrastructura de cloud public a fost dezvoltată pentru a asigura o disponibilitate ridicată a serviciilor în mod implicit și în fața unui eveniment care poate afecta centrele de date ale furnizorului.
Astăzi (nr. aprilie 2022), Google Cloud cuprinde 112 de zone combinate în 37 de regiuni. Ce sunt zonele și ce sunt regiunile?

Zona se referă la aria de disponibilitate, așa cum este determinată de utilizator la configurarea unui serviciu (de exemplu, mașini virtuale în Compute Engine). O zonă nu este un centru de date – există un strat de abstractizare între o zonă și un grup de mașini fizice în interiorul camerei serverului Google. O zonă poate consta dintr-unul sau mai multe astfel de grupuri, dar nu este atribuită permanent unor dispozitive specifice dintr-un anumit centru de date.
În același timp, o regiune cuprinde cel puțin trei zone. Zonele găsite într-o regiune au conexiuni cu lățime de bandă mare și cu latență redusă (sub 5 milisecunde).
Un utilizator Google Cloud Platform poate opta ca datele serviciului să fie găzduite:
- zonal – în cadrul unei zone,
- regional – în mai multe zone dintr-o regiune,
- multiregional – între două sau mai multe regiuni.
Când implementăm o aplicație în modelul zonal, suntem expuși riscului de eșec cauzat de exemplu de un dezastru natural. Implementarea unei aplicații în modelul regional garantează un nivel mai ridicat de disponibilitate datorită transferului de date și echilibrării sarcinii dintre resurse din diferite zone. Aceasta face posibilă reducerea la minimum a timpului de nefuncționare și menținerea unui nivel ridicat de disponibilitate chiar dacă are loc un eveniment major la centrul de date fizic. Modelul cu mai multe regiuni asigură disponibilitatea globală – de ex. peste continente – și oferă protecție împotriva efectelor unei eșecuri a unei întregi regiuni.
Deoarece datele nu sunt stocate pe anumite mașini, ci sunt în mod continuu divizate, replicate și distribuite între mașinile aflate în diferite locații, o defecțiune a centrului de date fizic nu are un impact prea mare asupra disponibilității unei aplicații găzduite în cloud.
În cazul unei eșec la centrul de date, resursele și accesul sunt transferate automat către un alt centru de date, astfel încât utilizatorii Google Cloud să nu aibă timp de nefuncționare atunci când folosesc aplicația afectată.
Centrele de date dispun și de generatoare de rezervă de urgență care furnizează energie clădirilor și mașinilor în cazul unei întreruperi de curent. Există de asemenea și administratori și specialiști în securitate care lucrează 24/7 în fiecare centru. Aceștia se asigură că atât serviciile și aplicațiile Google, cât și resursele clienților sunt pe deplin disponibile și operabile în mod continuu.
Planificarea și modelele de recuperare în caz de dezastru disponibile în Google Cloud Platform
Google Cloud face posibilă dezvoltarea unui scenariu de recuperare după dezastru pe baza următoarelor trei modele:
- rece – implicând o perioadă de nefuncționare a sistemului până când datele sunt restaurate,
- cald – implicând un timp scurt de nefuncționare, doar până când resursele de înlocuire sunt implementate,
- fierbinte – implicând o funcționare continuă a sistemului și, destul de des, soluționare sau recuperare automată.
Într-un videoclip din seria „Get cooking in Cloud”, atașat mai sus, Priyanka Vergadia descrie cele trei modele menționate folosind exemplul coacerii de prăjituri și torturi pentru o petrecere. Mixerul pe care îl folosește începe să facă niște zgomote deranjante, ceea ce înseamnă că dispozitivul se poate defecta în curând;
- în modelul rece, Priyanka poate să oprească pregătirile și să sune compania producătoare a mixerului pentru a repara dispozitivul; o astfel de soluție, totuși, o va încetini considerabil și îi va face imposibil să aibă prăjiturile și torturile pregătite la timp pentru petrecere,
- în modelul cald, poate să-și întrerupă pregătirile pentru un timp și să încerce să repare singură mixerul urmând instrucțiunile furnizate în manual; va pierde ceva timp, dar probabil va reuși să livreze totul la timp,
- în modelul fierbinte, ea continuă să folosească mixerul la o viteză lentă – mai sigură – și continuă cu pregătirile, hotărând să repare mai târziu mixerul.