Dane pochodzące z różnych źródeł generowane są w czasie rzeczywistym. Niestety ich przechwytywanie, przetwarzanie i analizowanie nie jest łatwe, ponieważ zwykle nie występują w formacie pożądanym przez dalsze systemy. Rozwiązaniem jest Dataflow dostępne w ramach Google Cloud Platform.

Czym jest Dataflow?
Dataflow to bezserwerowa, szybka w działaniu i niedroga usługa przetwarzania danych strumieniowych (stream data) oraz wsadowych (batch data). Eliminuje obciążenie operacyjne poprzez automatyzację udostępniania infrastruktury oraz automatyczne skalowanie, kiedy ilość danych rośnie. Innymi słowy, Google Cloud Dataflow jest usługą potoku danych (pipeline service) pozwalającą wdrożyć strumieniowanie w rurociągach (pipelines) Apache, które możesz budować za pomocą biblioteki Apache Beam.
Kiedy warto skorzystać z Dataflow?
Dataflow jest doskonałym wyborem do zastosowań, takich jak działająca w czasie rzeczywistym sztuczna inteligencja, hurtownia danych lub analiza strumieniowa. W jakich sytuacjach sprawdzi się Dataflow? Możesz go zastosować do analizy segmentacji w handlu detalicznym, strumienia kliknięć (clickstream) oraz punktu sprzedaży. Usługa ta pomoże również w wykrywaniu oszustw w usługach finansowych, pozwoli na spersonalizowanie doświadczenia użytkownika w grach oraz wesprze analitykę IoT w kluczowych branżach, takich jak produkcja, opieka zdrowotna, czy logistyka.
Usługę Dataflow z powodzeniem wdrożyło m.in. Renault. Już w 2016 francuska marka samochodowa rozpoczęła transformację cyfrową w ramach dostosowania się do wymogów Przemysłu 4.0. Jej konsekwencją była implementacja Google Cloud Platform. Od tego momentu usługa Dataflow stała się podstawowym narzędziem dla większości potrzeb związanych z przetwarzaniem danych na platformie. Renault wykorzystuje Dataflow do pozyskiwania i przekształcania danych z zakładów produkcyjnych, a także innych połączonych, kluczowych referencyjnych baz.

Źródło: Google Cloud Platform
Jak w praktyce skorzystać z Dataflow?
Korzystanie z Dataflow jest łatwe. Transformacja danych odbywa się w trzech krokach:
a) Przyjmowanie danych (ingest)
b) Przetwarzanie danych (process)
c) Analiza danych (analyze)
Wystarczy wczytać dane ze źródła, aby po przekształceniu zapisać je na wyjściu. Przenośność danych zapewniona jest przez potok przetwarzania danych, stworzony za pomocą open-sourcowej biblioteki Apache Beam, w wybranym przez ciebie języku. Dataflow wykonuje tak zadane zadania za pomocą roboczych maszyn wirtualnych.

Omawiane zadania możesz uruchamiać za pomocą interfejsu użytkownika Cloud Console, gCloud CLI lub API. Nie musisz samemu tworzyć instrukcji. Pomocne mogą okazać się gotowe lub niestandardowe szablony. Jeżeli piszesz instrukcje SQL samodzielnie, możesz tworzyć potoki bezpośrednio z interfejsu użytkownika BigQuery, albo korzystać a notatników AI Platform.
Dzięki Dataflow możesz skupić się na programowaniu, a nie na zarządzaniu klastrami serwerów. Bezserwerowe podejście Dataflow eliminuje również obciążenie operacyjne związane z inżynierią danych, a możliwość szybkiego, uproszczonego tworzenia potoku danych strumieniowych ogranicza opóźnienia.
Funkcje Dataflow w Google Cloud Platform
Autoskalowanie zasobów i dynamiczne równoważenie pracy
Minimalizacja opóźnień potoku, przy jednoczesnym zmaksymalizowaniu wykorzystania zasobów pozwala zmniejszyć koszty przetwarzania rekordów. Dzieje się tak dzięki automatycznemu skalowaniu zasobów danych. Dane wejściowe są automatycznie dzielone na partycje i stale równoważone, co pozwala wyrównać wykorzystanie zasobów i zmniejszyć wpływ klawiszy dostępu (hot keys) na wydajność potoku.
W przypadku autoskalowania mówimy zarówno o horyzontalnym, jak i wertykalnym. Autoskalowanie horyzontalne umożliwia usłudze Dataflow automatyczne wybieranie odpowiedniej liczby instancji roboczych wymaganych do uruchomienia zadania. Dataflow może również dynamicznie relokować większą lub mniejszą liczbę pracowników w czasie wykonywania zadania, co dzieje się na podstawie charakterystyki danego zadania.
Autoskalowanie wertykalne, będące nowością w opcji Dataflow Prime, dynamicznie dostosowuje moc obliczeniową przydzieloną każdemu pracownikowi na podstawie wykorzystania. Autoskalowanie w pionie współpracuje z wertykalnym, aby w płynny sposób dostosować się do potrzeb potoku.
Elastyczne planowanie i ceny przetwarzania wsadowego
Elastyczne planowanie zasobów (FlexRS) zapewnia niższą cenę przetwarzania wsadowego, kiedy konieczny jest elastyczny czas planowania zadań tak jak w przypadku np. zadań nocnych. Ustawiane są one w kolejce z gwarancją, że zostaną wybrane do wykonania w ciągu sześciu godzin.
Gotowe do użycia wzorce AI implementowane w czasie rzeczywistym
Dzięki gotowym do użycia wzorom, możliwości sztucznej inteligencji Dataflow w czasie rzeczywistym, pozwalają na reakcję, również w czasie rzeczywistym i zbliżoną do ludzkiej inteligencji na duże strumienie zdarzeń. Sprawia to, że klienci mogą tworzyć inteligentne rozwiązania, poczynając od analiz predykcyjnych, aż po personalizację w czasie rzeczywistym, oraz inne, bardziej zaawansowane przypadki użycia analiz.
Streaming Engine
Streaming Engine oddziela obliczenia od magazynu stanu i przenosi część wykonania potoku z roboczych maszyn wirtualnych do zaplecza usługi Dataflow, znacznie poprawiając autoskalowanie i opóźnienia danych.
Dataflow Shuffle
Oparte na usługach Dataflow Shuffle przenosi używaną do grupowania i łączenia danych operację losową (shuffle operation) z roboczych maszyn wirtualnych do back endu Dataflow. Potoki wsadowe, których dotyczy ta operacja, skalują się płynnie, bez konieczności dostrajania do setek terabajtów.
Dataflow SQL
Dataflow SQL pozwala wykorzystać twoją znajomość SQL do tworzenia strumieniowych potoków Dataflow bezpośrednio z internetowego interfejsu użytkownika BigQuery. Możesz połączyć przesłane strumieniowo dane z Pub/Sub z plikami w Cloud Storage lub tabelami w BigQuery, zapisywać wyniki w BigQuery i tworzyć panele w czasie rzeczywistym za pomocą Arkuszy Google lub innych narzędzi BI.
Integracja z notatnikami Vertex AI
Dataflow pozwala na iteracyjne budowanie potoków od podstaw przy wykorzystaniu notatników Vertex AI. Potoki wdrażane są za pomocą programu uruchamiającego Dataflow. Możesz tworzyć potoki z wykorzystaniem biblioteki Apache Beam, dokonując weryfikacji wykresu potoku według REPL (read-eval-print-loop). Notatniki, dostępne za pośrednictwem Vertex AI, pozwalają na pisanie potoków w intuicyjnym środowisku, wykorzystując do tego najnowsze struktury analizy danych i uczenia maszynowego.
Szablony Dataflow
Szablony umożliwiają łatwe udostępnianie potoków członkom zespołu oraz całej organizacji. Korzystając z wielu udostępnionych przez Google szablonów, możesz szybko wdrożyć proste, ale przydatne zadania przetwarzania danych. Dostępne są między innymi szablony zmiany przechwytywania danych (Change Data Capture), czy szablony Flex, dzięki którym możesz utworzyć szablon z dowolnego potoku Dataflow.
Przechwytywanie danych zmian w czasie rzeczywistym
Możesz usprawnić analizę strumieniową, synchronizując lub replikując dane z minimalnymi opóźnieniami w heterogenicznych źródłach danych. Rozszerzalne szablony Dataflow integrują się z Datastrem, co pozwala replikować dane z Cloud Storage do BigQuery, PostgreSQL lub Cloud Spannera. Debezium, łącznik Apache Beam, zapewnia open-sourcową opcję do pozyskiwania zmian danych z MySQL, PostreSQL, SQL Server oraz Db2.
Monitoring liniowy (inline monitoring)
Monitoring liniowy jest wbudowaną funkcją, umożliwiającą bezpośredni dostęp do metryk zadań, co pomaga w rozwiązywaniu problemów z potokami wsadowymi i strumieniowymi. Możesz dzięki niemu uzyskać dostęp do wykresów monitorowania zarówno na poziomie jednego kroku, jak i pracownika. Pozwala ci to również ustalać alerty dotyczące takich warunków jak nieaktualne dane, czy duże opóźnienia systemu.
Zarządzane przez klienta klucze szyfrowania
Możesz tworzyć potok wsadowy lub strumieniowy chroniony za pomocą klucza szyfrowania zarządzanego przez klienta (CMEK – cutomer-managed encription key) lub też uzyskać dostęp do danych chronionych przez CMEK w źródłach (sources) i ujściach (sinks).
Integracja z VPC Service Controls
Dzięki tej integracji możliwe jest dodatkowe zabezpieczenie środowiska przetwarzania danych. Ogranicza to ryzyko ich eksfiltracji.
Private IP
Wyłączenie publicznych adresów IP pozwala lepiej zabezpieczyć infrastrukturę przetwarzania danych. Dzięki rezygnacji z publicznych adresów IP dla pracowników Dataflow wpływasz na zmniejszenie liczby używanych publicznych adresów IP w ramach swojego projektu Google Cloud.
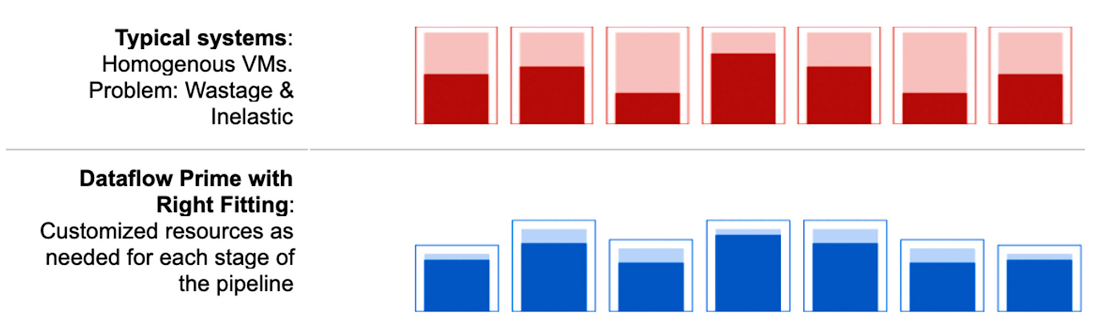
Właściwe dopasowania – nowa funkcja w opcji Prime
Dzięki właściwemu dopasowaniu (right fitting) tworzone są pule zasobów dla poszczególnych etapów. Są one zoptymalizowane dla każdego etapu, co skutkuje zmniejszeniem marnotrawstwa zasobów.
Inteligentna diagnostyka – nowy pakiet funkcji w opcji Prime
W ramach pakietu znajdziemy trzy funkcje. Pierwsza związana jest z zarządzaniem potokiem danych w oparciu o SLO. Druga umożliwia wizualizację zadań, dzięki czemu można monitorować wykresy zadań i szybko zidentyfikować wąskie gardła. Trzecia funkcja to automatyczne zalecenia w celu identyfikowania i dostosowywania problemów z wydajnością i dostępnością.

Czy Dataflow jest bezpiecznym rozwiązaniem?
Google zapewnia, że wszystkie dane są szyfrowane. Zarówno w stanie spoczynku, jak i podczas przesyłania, przy wykorzystaniu kluczy szyfrowania zarządzanych przez klienta. Dodatkowo możesz użyć prywatnych adresów IP i kontroli usług VPC, aby zabezpieczyć środowisko danych.
Ile kosztuje Dataflow?
Podobnie jak większość serwisów w ramach Google Cloud Platform, również Dataflow działa w modelu sekundowego naliczania kosztów. Oceniane jest rzeczywiste wykorzystanie wsadowych lub strumieniowych procesów. Kiedy Dataflow współpracuje z dodatkowymi zasobami, takimi jak Cloud Storage, czy Pub/Sub, to są one rozliczane zgodnie z osobnym cennikiem dla danej usługi.
Jeżeli chcesz dowiedzieć się więcej o tym jak wdrożyć zaawansowaną analitykę w firmie i skalować biznes z pomocą usług Google Cloud, pobierz nagranie z meetupu „Biznes oparty na danych w chmurze”