Spis treści
Powiedzenie o dwóch grupach ludzi i backupie jest tak powszechne, że chyba nie warto go po raz kolejny przytaczać. Warto za to pokazać, jak niewielkim wysiłkiem wykonać kopię zapasową – a najlepiej ustawić regularne, automatyczne wykonanie backupu.
Zaplanowanie wykonania kopii zapasowej według niższego tutorialu zajmie kilkanaście minut, a pozwoli zaoszczędzić godziny odzyskiwania danych lub tworzenia ich od nowa.
Na początek kilka słów teorii – o samej kopii zapasowej, miejscu jej przechowywania oraz o tym, czym jest cron.
Czym jest kopia zapasowa?
Kopia zapasowa jest nazywana też kopią bezpieczeństwa lub, bardziej potocznie, backupem.
Polega na skopiowaniu wartościowych danych – dokumentów, plików, grafik – i umieszczeniu ich w innej, bezpiecznej lokalizacji. Takie działanie jest kluczowe dla przywracania informacji po awarii, zachowania ciągłości funkcjonowania aplikacji czy zapewnienia spokojnego snu pracownikom działu IT.
Jak często prowadzić backup?
Nie ma na to pytanie uniwersalnej odpowiedzi.
To zależy od tego, jak często w aplikacji czy bazie danych zachodzą zmiany, ile ich jest i jaka jest ich waga. W przypadku niektórych serwisów wystarczy przeprowadzić kopię zapasową raz w tygodniu, w przypadku innych dobrze będzie robić backup co godzinę.
Gdzie przechowywać kopię zapasową?
Z pewnością w innym miejscu, niż oryginalny, kopiowany plik. Jeśli baza danych znajduje się na fizycznym serwerze, backup lepiej umieścić na innym urządzeniu lub w chmurze. Jeśli dane aplikacji oryginalnie znajdują się w chmurze, backup możemy zapisać w innej instancji (nawet w odległym regionie) czy na rozwiązaniu innego, zaufanego dostawcy usług chmurowych.
Zobacz też:
- Disaster Recovery Plan, czyli jak zachować dostępność aplikacji w obliczu awarii
- Business Continuity Plan – czym jest i jak go stworzyć?
W jaki sposób można robić kopię zapasową bazy danych?
Backup można robić ręcznie. Jednak trzeba być naprawdę zdyscyplinowanym, żeby zachować regularność wykonywania kopii zapasowej i mieć pewność, że na żadnym kroku nie popełni się błędu.
Lepszym rozwiązaniem jest automatyzacja wykonania kopii zapasowej – za pomocą gotowej usługi lub własnego programu do backupu. Automatyzacja da pewność, że kopia została wykonana prawidłowo, o określonej porze, a Ty zaoszczędzisz przy okazji trochę czasu.
Jeśli posiadasz bazę danych w usłudze Cloud SQL w Google Cloud Platform, możesz skorzystać z wbudowanej możliwości automatyzacji prowadzenia kopii zapasowej. A jeśli chcesz stworzyć swój program do backupu, czytaj dalej. Opisaliśmy sposób, który obejmuje skrypt Node.js, używa crona i zapisuje kopię bazy danych w usłudze Cloud Storage. Analogiczny program można napisać w innym języku, który posiada sterownik do bazy danych MySQL – na przykład Python, Go czy C#.
Co to jest cron i jaką rolę odgrywa w opisanym programie do backupu?
Cron to program do harmonogramowania zadań dostępny w systemach operacyjnych z rodziny Unix. W określonym terminie cron wykona powierzone mu zadanie – na przykład uruchomi skrypt lub wykona przypisaną komendę co piątek o godzinie 23:00.
Cronowi trzeba przedłożyć jasne instrukcje:
- gdzie ma wykonać akcję (ścieżka dotarcia, np. do pliku, folderu, programu),
- jaką akcję ma wykonać (np. odpalić skrypt, wykonać komendę, przesłać plik),
- kiedy ma to zrobić (np. co pół godziny, co poniedziałek, raz na miesiąc).
Ten zestaw informacji – częściowo zapisany w kodzie, częściowo w ustawieniach crona – jest nazywany cron job.
W przypadku programu do backupu wskażemy za pomocą komend w Node.js, że cron codziennie o godzinie 1.00 ma skopiować bazę danych znajdującą się na serwerze i zapisać ją w zasobniku Cloud Storage o nazwie cron-backup.
Ustawienie terminu wykonania działania
Podczas tworzenia crona będziemy wskazywać, z jaką częstotliwością ma on wykonywać zlecone zadanie.
Mamy możliwość wskazania:
- godziny (zakres 0-23) z dokładnością do minuty (zakres 0-59),
- dnia miesiąca (wartości od 1 do 28, 29, 30 lub 31 – w zależności od długości miesiąca),
- miesiąca (wartości od 1 do 12),
- dnia tygodnia (wartości w zależności od rodzaju crona – 0-6 lub 1-7).
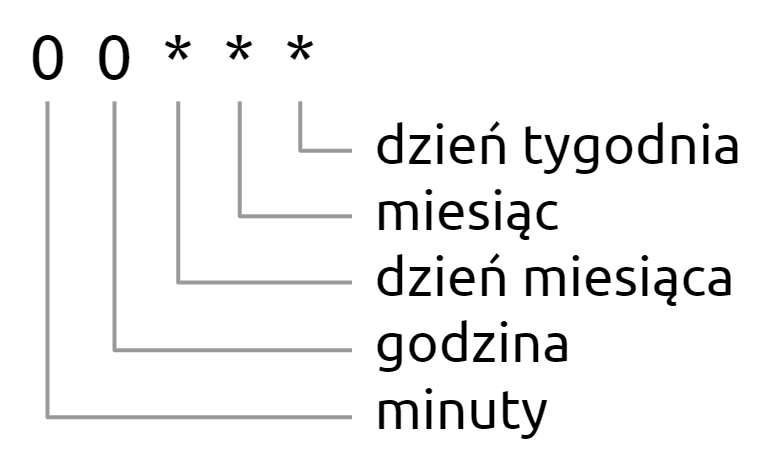
Wstawiając liczby w odpowiednie miejsca, możemy wskazać jeden termin, kilka terminów lub zakres dat. Gwiazdka oznacza, że cron będzie wykonywał akcję cyklicznie w najkrótszym możliwym odstępie, np. codziennie.
Przykładowo:
- 0 0 * * * – cron wykona akcję codziennie o północy,
- 30 1 * * 1 – co poniedziałek o godzinie 1.30,
- 0 22 * * 1-5 – codziennie od poniedziałku do piątku o godzinie 22.00,
- 0 12 10 * * – 10. dnia miesiąca o godzinie 12.00,
- 0 20 1-5 * * – w 1., 2., 3., 4. i 5. dzień miesiąca o godzinie 20.00,
- 59 23 31 12 * – o godzinie 23.59 w dniu 31 grudnia.
Żeby prawidłowo wyznaczyć termin uruchomienia crona, warto skorzystać chociażby z crontab.guru – edytora harmonogramu crona online.
Nie tylko kopia zapasowa – do czego jeszcze można użyć crona?
Cron nie jest dedykowany jedynie do robienia kopii zapasowej. Z jego pomocą można zautomatyzować wiele działań – m.in. prowadzić monitoring logów, generować raporty czy przesyłać newslettery. Wszystko zależy od tego, jaki skrypt przygotujemy.
Crona można “zatrudnić” między innymi do:
- monitorowania przestrzeni na dysku,
- prowadzenia analizy logów,
- cyklicznej zmiany adresu IP,
- czyszczenia bazy danych,
- aktualizacji raportów, wykresów czy dashboardów o nowe dane,
- odświeżanie listy produktów w sklepie internetowym,
- wyłączanie maszyn wirtualnych ze środowiskami developerskimi i testowymi po godzinach pracy,
- agregowanie na skrzynkę nowych artykułów opublikowanych na portalu Hacker Noon z tagiem #security,
- przesyłanie współpracownikom raz w roku mailowego życzenia “smacznego” w Dzień Pizzy.
Program do backupu w Node.js z użyciem crona – tutorial
Wymagania początkowe
- system operacyjny z rodziny Unix,
- baza danych MySQL,
- korzystanie z usługi Cloud Storage na Google Cloud Platform,
- znajomość Node.js.
W tutorialu używamy Node.js w wersji 13.12.0 i npm w 6.14.8.
Inicjalizacja projektu
Zaczniemy od stworzenia skryptu, który będzie tworzył backup bazy danych.
Tworzymy nowy folder i rozpoczynamy od zainicjowania projektu poprzez wpisanie komendy:
npm init -y

Skrypt wykonujący backup bazy danych
Będziemy używać biblioteki mysqldump (więcej informacji o paczce).
Instalujemy paczkę, wpisując komendę:
npm install mysqldump

Tworzymy plik o nazwie index.js i dodajemy w nim kod, który będzie odpowiadał za stworzenie kopii zapasowej bazy danych:
const mysqldump = require('mysqldump')
const dumpFileName = `${new Date(Date.now()).toISOString()}.dump.sql`
const createBackup = async () = {
const connection = {
host: 'localhost',
user: 'root',
password: 'password',
database: 'employees',
}
try {
await mysqldump({
connection,
dumpToFile: dumpFileName
});
} catch(error) {
console.error(error)
}
}
createBackup()
W kodzie wyżej, w sekcji connection, wprowadź informacje o swojej bazie danych (host, user, password, database).
Żeby sprawdzić, czy kod działa, wpisujemy:
node index.js
Po pomyślnej konfiguracji w folderze zostanie utworzony plik z danymi. W nazwie pliku powinna znaleźć się data utworzenia.
Połączenie z Google Cloud Storage
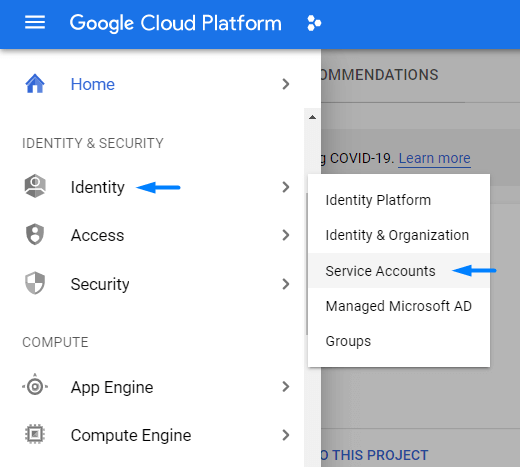
W konsoli Google Cloud Platform tworzymy service account, czyli konto usługi. Możesz zrobić to w zakładce IAM & Admin > Service Accounts lub Identity > Service Accounts (to ten sam panel, z tymi samymi funkcjonalnościami; Google wprowadza obecnie lekkie zmiany w UI konsoli – grudzień 2020).

Nadajemy nowemu kontu usługi uprawnienia do Cloud Storage (np. rolę Storage Object Creator).
Na podstawie naszego service account tworzymy klucz w formacie JSON. Nazwę klucza zmieniamy na gcs.json.
Następnie tworzymy bucket (zasobnik) w usłudze Cloud Storage.
Można to zrobić na dwa sposoby:
- w Cloud Shellu poprzez wpisanie komendy:
gsutil mb gs://nazwa-bucketu
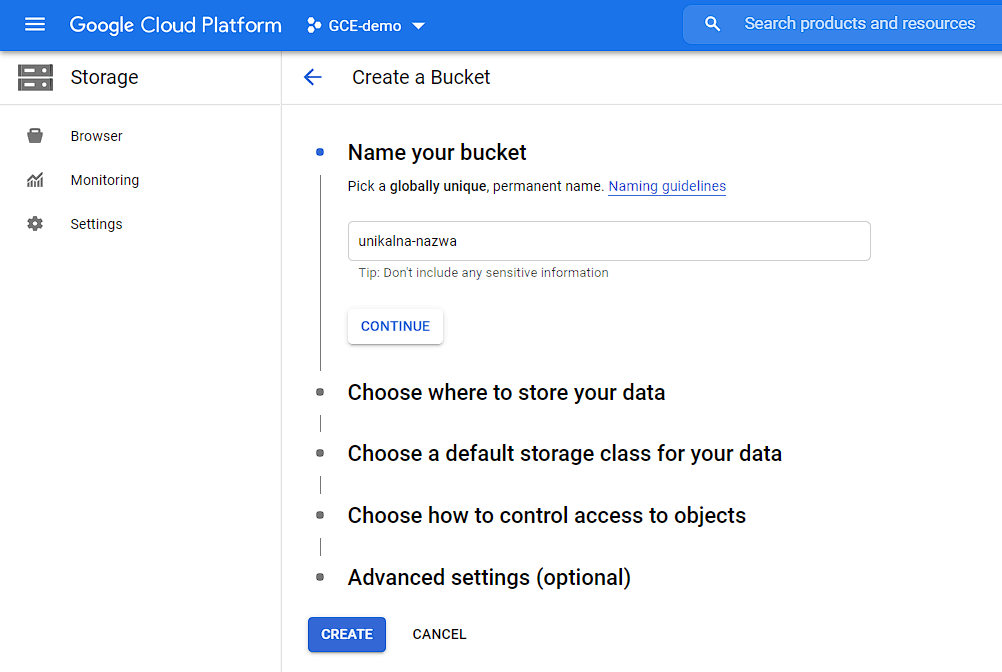
- lub w usłudze Cloud Storage – przechodzimy do zakładki Storage w menu po lewej i klikamy create bucket:

Wpisujemy nazwę bucketu:
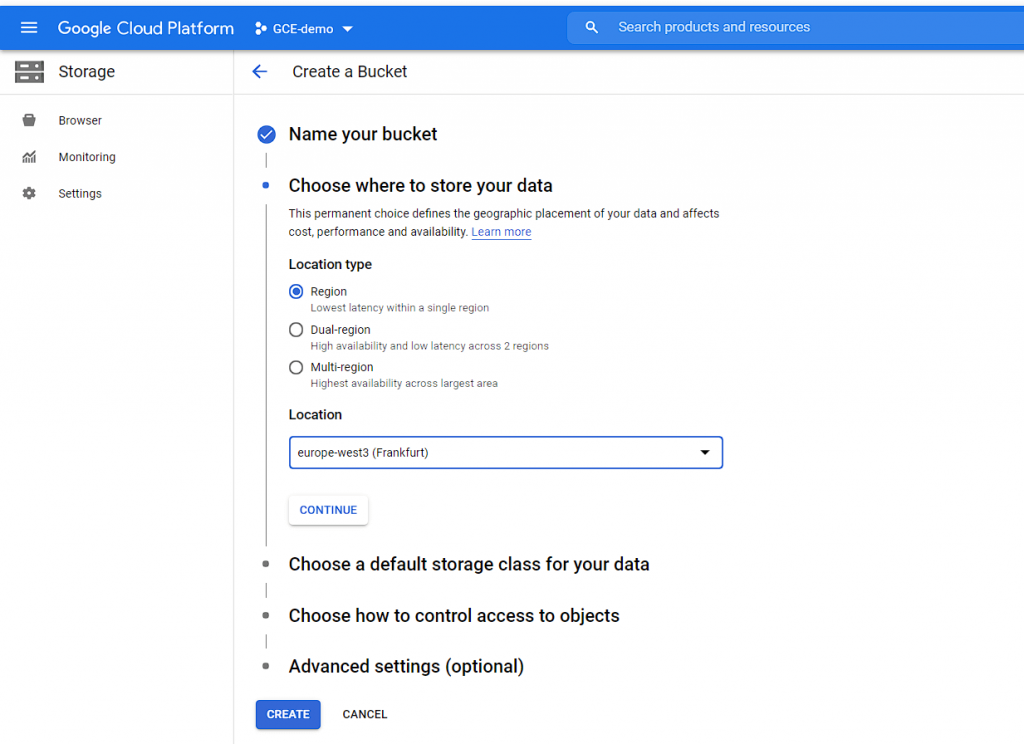
Wybieramy region – najbliżej Polski jest region europe-west3 (Frankfurt):
Następnie instalujemy w terminalu paczkę do Node.js obsługującą Google Cloud Storage. Robimy to za pomocą komendy:
npm install google-cloud/storage
Tworzymy nowy plik o nazwie sendDataToBucket.js i wklejamy poniższy kod:
const { Storage } = require('@google-cloud/storage');
const bucketName = 'cron-backup';
const sendDataToBucket = async (file) ={
try {
const storage = new Storage({
projectId: 'cron-backup',
keyFilename: './gcs.json',
});
await storage
.bucket(bucketName)
.upload(`${__dirname}/${file}`, {
gzip: true,
metadata: {
cacheControl: 'public, max-age=31536000',
},
});
await storage.bucket(bucketName).file(`${__dirname}/${file}`)
} catch (error) {
console.error(error);
}
};
module.exports = sendDataToBucket;
Po uruchomieniu kodu komendą node index.js powinniśmy w Cloud Storage otrzymać następujący widok:
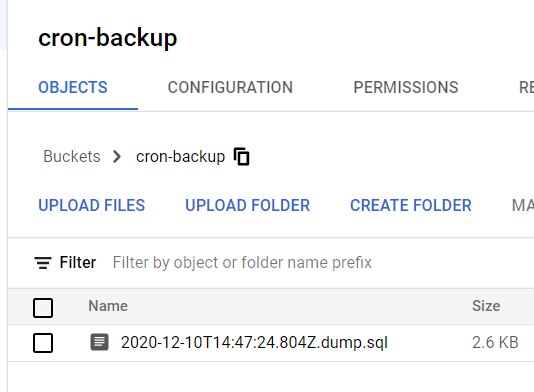
Dla czystości kodu zmienimy nieco strukturę programu do backupu. Struktura powinna wyglądać następująco:

Plik createBackup.js powinien zawierać:
const mysqldump = require('mysqldump');
const dumpFileName = `${new Date(Date.now()).toISOString()}.dump.sql`;
const createBackup = async () = {
const connection = {
host: 'localhost',
user: 'root',
password: 'password',
database: 'employees',
}
try {
await mysqldump({
connection,
dumpToFile: dumpFileName
});
return dumpFileName
} catch(error) {
console.error(error)
}
}
module.exports = createBackup
Plik index.js:
const sendDataToBucket = require('./sendDataToBucket');
const createBackup = require('./createBackup')
const main = async () = {
const filename = await createBackup()
console.log(filename)
await sendDataToBucket(filename)
}
main()
Plik sendDataToBucket.js powinien zawierać kod:
const { Storage } = require('@google-cloud/storage');
const bucketName = 'cron-backup';
const sendDataToBucket = async (file) = {
try {
const storage = new Storage({
projectId: 'cron-backup',
keyFilename: './gcs.json',
});
await storage
.bucket(bucketName)
.upload(`${__dirname}/${file}`, {
gzip: true,
metadata: {
cacheControl: 'public, max-age=31536000',
},
});
await storage.bucket(bucketName).file(`${__dirname}/${file}`)
} catch (error) {
console.error(error);
}
};
module.exports = sendDataToBucket;
Stworzenie crona, który będzie wywoływał kod
Wpisujemy w terminalu: crontab -e.
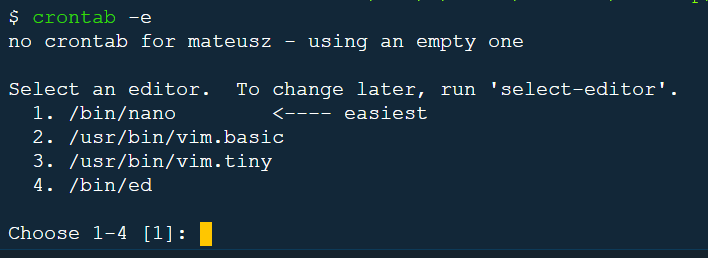
Wybieramy 1.
Zostaniemy przeniesieni do pliku, gdzie zdefiniujemy cron jobs.
Załóżmy, że chcemy odpalić program do backupu codziennie o godzinie 1.00 w nocy. Pierwsza część cron job to wyzwalacz, czyli termin wykonania zadania – 0 1 * * * (przypomnijmy: minuta, godzina, dzień miesiąca, miesiąc, dzień tygodnia). Druga część wskazuje ścieżkę do programu do backupu, czyli aplikacji w Node.js.
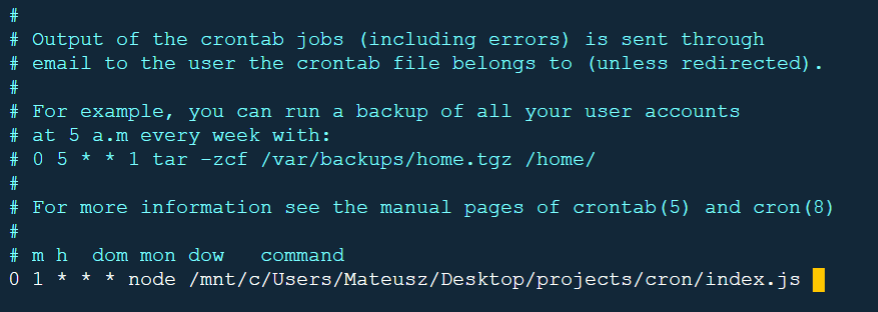
I to wszystko. Po zatwierdzeniu program do backupu będzie działał, a kopia zapasowa będzie wykonywana i zapisywana codziennie w Cloud Storage o godzinie 1.00 w nocy.
Kod do aplikacji jest dostępny na GitLab: gitlab.com/machmielewski/node-mysql-to-gcs